Ứng dụng công nghệ trí tuệ nhân tạo trong bài toán phân loại văn bản
Giới thiệu chung về bài toán phân loại văn bản trong xử lý ngôn ngữ tự nhiên
Ứng dụng của công nghệ phân loại hiện nay đang phát triển rất mạnh ở rất nhiều lĩnh vực (học thuật, kinh doanh, bảo mật, y tế...) và các đối tượng (nhà nghiên cứu xã hội, chính phủ và các tổ chức phi lợi nhuận khác). Vì các tổ chức này sở hữu một lượng lớn dữ liệu không có cấu trúc và việc xử lý dữ liệu sẽ trở nên dễ dàng hơn rất nhiều nếu như các dữ liệu này được chuẩn hóa bởi các chủ đề/nhãn. Nền tảng công nghệ để thực hiện bài toán phân loại văn bản chính là trí tuệ nhân tạo (Artificial Intelligence – AI) và học sâu (Deep Learning).
Bên cạnh đó, trong những năm gần đây, ứng dụng mạng xã hội vào hoạt động kinh tế đang đạt được những lợi ích chưa từng có. Các doanh nghiệp có thể thu thập các đánh giá của khách hàng về các sản phẩm và dịch vụ của họ. Điều này là cơ sở để tái phát minh các chiến lược kinh doanh kế tiếp, sao cho phù hợp với người tiêu dùng. Việc phân tích xã hội sử dụng một lượng dữ liệu khổng lồ từ các mạng xã hội để đưa ra các quyết định chiến lược. Các doanh nghiệp sử dụng các kỹ thuật và công cụ học máy để xác định các mẫu và xu hướng, từ đó có được các thông tin hữu ích. Việc gán nhãn cho nội dung hoặc sản phẩm sử dụng các danh mục cũng là một cách để cải thiện việc duyệt web hoặc xác định nội dung liên quan trên trang web. Các lĩnh vực như thương mại điện tử, truyền thông có thể sử dụng công nghệ tự động để phân loại và gán nhãn cho nội dung và sản phẩm [5]. Hay một hệ thống phản ứng khẩn cấp có thể được thực hiện hiệu quả hơn bằng cách phân loại các cuộc trò chuyện, trao đổi trên phương tiện truyền thông xã hội. Các nhà chức trách có thể theo dõi và phân loại tình huống khẩn cấp để phản ứng nhanh nếu có bất kỳ tình huống nào phát sinh. Đây là trường hợp phân loại rất chọn lọc. Một bài viết được xây dựng trên một hệ thống phản ứng khẩn cấp như vậy được trình bày trong [6].
Bài toán phân loại văn bản là một trong những nội dung của xử lý ngôn ngữ tự nhiên. Đó là vấn đề xây dựng các mô hình mà có thể phân loại các tài liệu mới vào các chủ đề đã được xác định trước [1, 2]. Đây là một quá trình xử lý phức tạp, không chỉ liên quan đến việc huấn luyện các mô hình mà cần thực hiện nhiều bước khác nhau như: tiền xử lý dữ liệu, chuyển đổi dữ liệu, giảm kích thước của dữ liệu [3]. Để phân loại văn bản cần sử dụng các kỹ thuật khác nhau và triển khai trong các hệ thống phức tạp. Hiện nay, có hai hướng phát triển hệ thống phân loại: phát triển các hệ thống phân loại mới, hoặc cải tiến các hệ thống có sẵn để đạt kết quả tốt hơn.
Ở Việt Nam, cộng đồng nghiên cứu trí tuệ nhân tạo xử lý ngôn ngữ tự nhiên để áp dụng vào bài toán xử lý tiếng Việt đang rất phát triển. Do đặc thù của tiếng Việt và sự khác biệt về bộ ngôn ngữ trong các thư viện, công cụ hỗ trợ, nên cộng đồng các nhà nghiên cứu AI của Việt Nam đã xây dựng và phát triển một số các thuật toán, thư viện và công cụ dành riêng cho tiếng Việt. Một số doanh nghiệp và trường đại học hoạt động trong lĩnh vực công nghệ thông tin đã và đang nghiên cứu đưa bài toán phân loại văn bản vào ứng dụng thực tế như: Framgia, Đại học Lê Quý Đôn [7], FPT, Đại học Khoa học Công nghệ thuộc Đại học Quốc gia Việt Nam [8, 9]…. Còn trong lĩnh vực quân sự, do là là môi trường đặc thù, vì vậy, việc thu thập thông tin trên các trang báo điện tử, diễn đàn, mạng xã hội,… để theo dõi tình hình, nắm bắt thông tin là một trong những nhiệm vụ mới, quan trọng trên không gian mạng. Do lượng thông tin thu thập được qua mạng Internet là rất lớn, nên đã đặt ra yêu cầu phân tích và xử lý lượng dữ liệu khổng lồ trên một cách tự động và nhanh chóng.
Đề xuất mô hình phân loại văn bản sử dụng các thuật toán học máy
Hình 1 mô tả quy trình xây dựng mô hình phân loại văn bản sử dụng các thuật toán học máy, gồm hai quá trình: huấn luyện và dự đoán.
Đầu vào của quá trình huấn luyện là các dữ liệu văn bản và các nhãn tương ứng với chủ đề cần phân loại. Quá trình này gồm 3 bước: tiền xử lý văn bản, trích xuất đặc trưng và huấn luyện sử dụng các thuật toán học máy.
Đầu ra của quá trình huấn luyện là mô hình được xây dựng và các tham số tối ưu tương ứng cho mô hình.
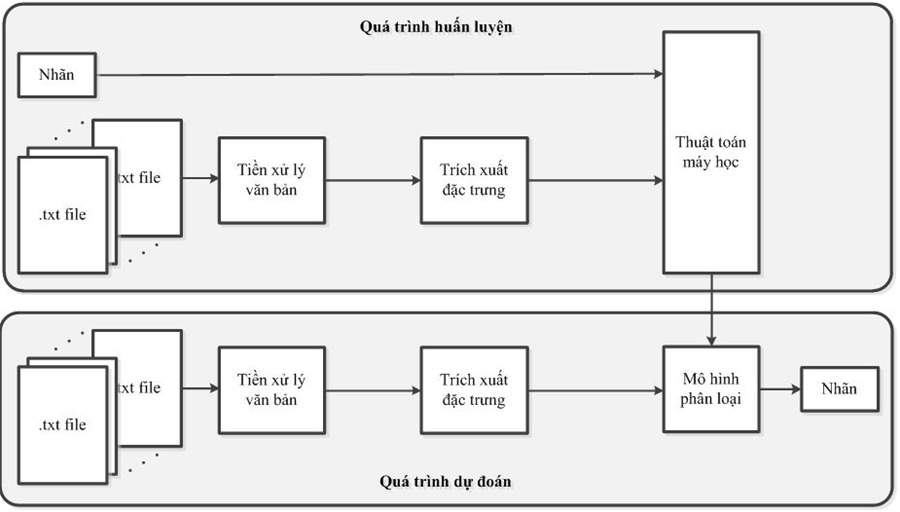
Hình 1. Quy trình xây dựng mô hình phân loại văn bản sử dụng các thuật toán máy học
Bước tiền xử lý văn bản gồm 4 công đoạn:
1. Thực hiện làm sạch dữ liệu để loại bỏ tạp nhiễu nhằm có kết quả xử lý dữ liệu tốt. Đa phần tạp nhiễu là các thẻ HTML, JavaScript.
2. Thực hiện tách từ - một công đoạn quan trọng bậc nhất trong xử lý ngôn ngữ tự nhiên, do Tiếng Việt có độ phức tạp hơn ngôn ngữ khác (bởi có các từ ghép). Việc tách từ theo nhiều cách khác nhau có thể gây ra sự hiểu nhầm về mặt ngữ nghĩa. Tuy nhiên, có một số công cụ hỗ trợ thực hiện việc này, phổ biến nhất là VnTokenizer.
3. Chuẩn hóa từ để đưa văn bản từ các dạng không đồng nhất về cùng một dạng (ví dụ tất cả đều chuẩn về chữ thường). Việc tối ưu bộ nhớ lưu trữ và tính chính xác cũng rất quan trọng. Có nhiều cách viết, mỗi cách viết khi lưu trữ sẽ tốn dung lượng bộ nhớ khác nhau (như half size chỉ tốn 1/2 dung lượng so với full size). Do đó, tuỳ theo nhu cầu, tình hình thực tế để đưa văn bản về một dạng đồng nhất.
4. Loại bỏ những từ không có ý nghĩa (stop words) mà xuất hiện nhiều trong ngôn ngữ tự nhiên. Có 2 cách chính để loại bỏ stop words, đó là dùng từ điển hoặc dựa theo tần suất xuất hiện. Bài báo này sử dụng phương pháp từ điển là phương pháp đơn giản nhất tạo một từ điển gồm những từ không có ý nghĩa và tiến hành lọc các tệp tin văn bản để loại bỏ những từ xuất hiện trong từ điển stop words.
Bước trích xuất đặc trưng gồm 2 bước là xây dựng từ điển và tạo vector số cho các văn bản theo phương pháp túi đựng từ (Bag of word - BoW). Tất cả các từ trong văn bản cần được chuyển thành dạng biểu diễn số. Cách đơn giản nhất là xây dựng một bộ từ điển, sau đó thay thế từ đó bằng thứ tự xuất hiện trong từ điển. Bài báo này sử dụng thư viện gensim để xây dựng từ điển. Sau đó tiến hành xây dựng từ điển chứa tất cả các từ trong tập dữ liệu sau khi đã tiến hành tách từ và loại bỏ stop words. Bước tạo vector số cho các văn bản sử dụng phương pháp túi đựng, thực hiện chạy từ đầu đến cuối văn bản, gặp từ nào thì sẽ cho vào túi đựng từ. Cuối cùng sẽ thu được vector thuộc tính cho từng file trong tập dữ liệu. Mỗi vector sẽ có độ dài chính bằng số từ trong từ điển.
Bước xây dựng mô hình các thuật toán học máy sẽ huấn luyện một bộ phân loại sử dụng các vector thuộc tính của dữ liệu ở trên. Có nhiều mô hình học máy có thể được sử dụng để huấn luyện tạo ra mô hình cuối cùng. Bài báo này sử dụng mô hình mạng nơron để huấn luyện. Hình 2 chỉ ra một ví dụ về cấu hình mạng nơron được thiết kế cho quá trình huấn luyện gồm lớp đầu vào, các lớp ẩn và lớp đầu ra.
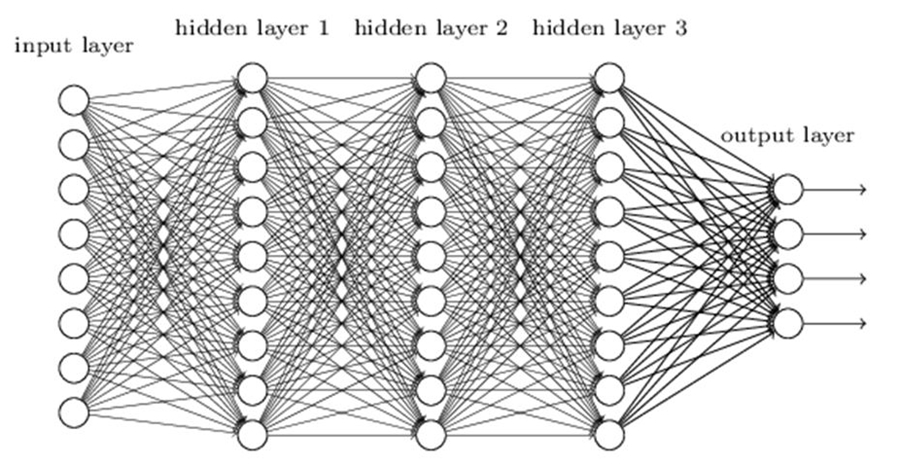
Hình 2. Ví dụ mô hình mạng nơron gồm lớp đầu vào, 3 lớp ẩn và lớp đầu ra
Hình 3 trình bày quá trình dự đoán nhãn cho dữ liệu mới đầu vào sử dụng mô hình đã được huấn luyện. Các dữ liệu đầu vào được thực hiện tiền xử lý và trích xuất đặc trưng dữ liệu (tương tự như bước 1 và 2 trong quá trình huấn luyện). Sau đó, các vector thuộc tính dữ liệu được đưa vào đầu vào của mô hình đã huấn luyện, đầu ra sẽ là các nhãn (các nhãn là các chủ đề của mô hình huấn luyện) tương ứng với các file văn bản đầu vào.
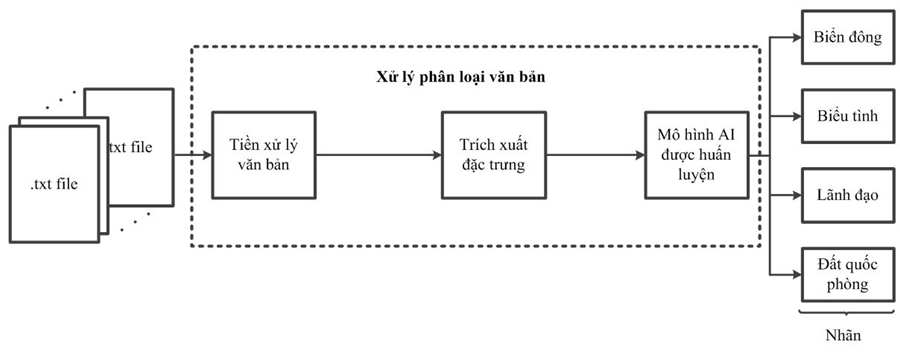
Hình 3. Quá trình dự đoán được đề xuất cho các loại nhãn
Ứng dụng bài toán phân loại văn bản vào xử lý thông tin trong lĩnh vực quân sự
Phần này sẽ giới thiệu quá trình thu thập dữ liệu và thiết kế mô hình mạng nơron để thực hiện bài toán phân loại văn bản với dữ liệu thu thập được. Dữ liệu từ các trang tin tức trực tuyến như VnExpress, Dantri, VTCNews… được thu thập và phân loại vào 4 chủ đề: biển đông, biểu tình, lãnh đạo và đất quốc phòng. Mỗi chủ đề gồm 200 file định dạng .txt và được chia thành 2 tập riêng biệt (100 file cho huấn luyện (training) và 100 file cho kiểm tra). Mô hình được thiết kế gồm 2 lớp ẩn mỗi lớp có 512 nơ ron và lớp đầu ra 4 nơron tương ứng với 4 chủ đề cần phân loại. Hình 4 chỉ ra các tham số cụ thể của mỗi lớp trong mô hình. Mô hình được huấn luyện sử dụng các dữ liệu thu thập được với 100 file cho mỗi chủ đề với các tham số như sau: loss = ‘categorical_crossentropy’, optimizer = ‘adam’, metrics = [‘accuracy’], epochs = 25.
Mô hình sau khi được huấn luyện được sử dụng để kiểm tra dữ liệu testing. Chất lượng của mô hình được đánh giá thông qua độ chính xác phân loại của tập dữ liệu testing.
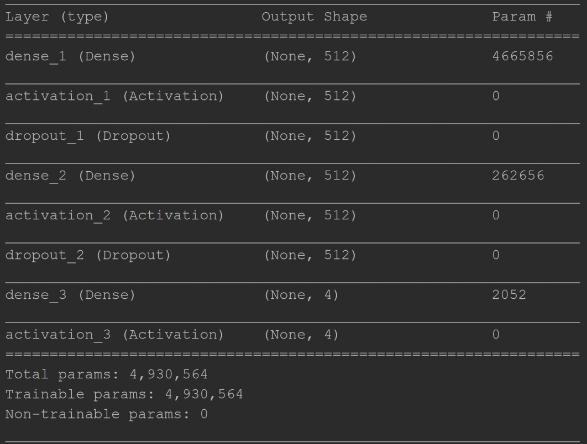
Hình 4. Các lớp và các tham số tương ứng của mô hình đề xuất
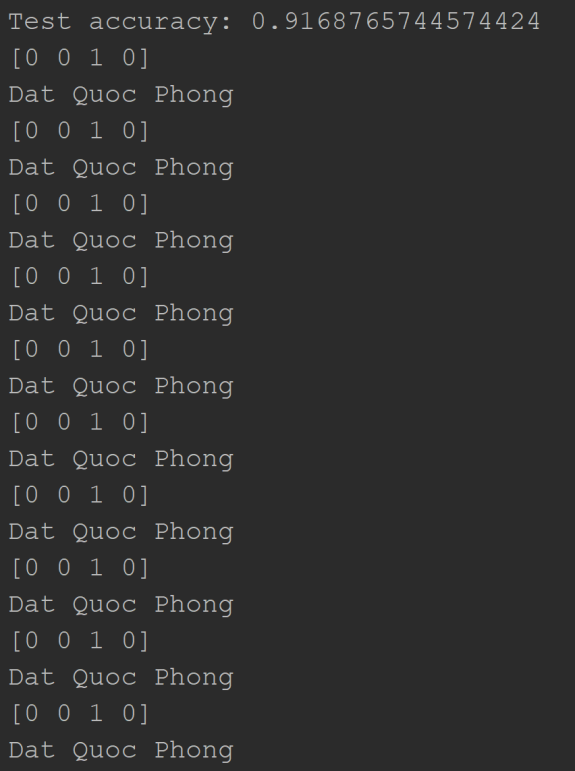
Hình 5. Độ chính xác của mô hình phân loại văn bản sử dụng tập dữ liệu kiểm tra
Hình 5 chỉ ra kết quả độ chính xác của mô hình phân loại văn bản sử dụng tập dữ liệu kiểm tra đạt 91.68%. Theo đó, kết quả phân loại cho 10 file đầu tiên trong tập testing được phân loại đúng.

Hình 6. Sử dụng mô hình được huấn luyện để phân loại nhãn cho dữ liệu thực tế
Để kiểm tra chất lượng phân loại văn bản của mô hình được huấn luyện, chúng tôi đã thử nghiệm với một số dữ liệu ngẫu nhiên được thu thập về từ các trang báo điện tử như 3 file văn bản phía dưới gồm “test1_bd”, “test1_dqp” và “test1”. Kết quả phân loại cho 3 file này ở Hình 6 là đúng theo các chủ đề. Kết quả này phần nào đã chứng minh được hiệu quả của mô hình được huấn luyện.


Hình 7. Một số mẫu văn bản được thu thập
Kết luận
Bài báo này đã giới thiệu ứng dụng mô hình mạng nơron để xử lý bài toán phân loại văn bản tự động trong lĩnh vực quân sự. Các bước trong quá trình phân loại văn bản đã được làm chủ từ việc thu thập dữ liệu, thiết kế mô hình cho đến quá trình huấn luyện và kiểm tra đánh giá chất lượng mô hình. Mô hình được huấn luyện đạt được độ chính xác phân loại 91.68%. Kết quả nghiên cứu này mở ra nhiều ứng dụng mới của công nghệ AI 4.0 trong lĩnh vực quân sự.
|
Tài liệu tham khảo [1]. Liu, B. “Web data mining: Exploring hyperlinks, contents, and usage data (data centric systems and applications)”, Secaucus, NJ, USA: Springer-Verlag New York, Inc.. [2]. Manning, C.D., Raghavan, P., and Schutze, H., “Introduction to information retrieval.”, New York, NY, USA: Cambridge University Press. [3]. Marcin Michal Mironczuk, Jaroslaw Protasiewicz, “A recent overview of the state-of-the-art elements of text classification”, Elsevier, Expert Systems with applications vol.106, pp.36-54, 2018. [4]. A. S. Halibas, A. S. Shaffi and M. A. K. V. Mohamed, "Application of text classification and clustering of Twitter data for business analytics," 2018 Majan International Conference (MIC), Muscat, 2018, pp. 1-7. [5]. https://towardsdatascience.com/text-classification-applications-and-use-cases-beab4bfe2e62 [6]. https://blog.paralleldots.com/research/artificial-intelligence-can-make-public-transportation-safer/ [7]. Toan Pham Van and Ta Minh Thanh, “Vietnamese news classification based on BoW with Keywords Extraction and Neural Network”, 21st Asia Pacific Symposium on Intelligent and Evolutionary Systems (IES), 2017. [8]. Thai-Hoang Pham and Phuong Le-Hong, “Content-based Approach for Vietnamese Spam SMS Filtering.”, May 2017. [9]. Thai-Hoang Pham and Phuong Le-Hong, “End-to-end Recurrent Neural Network Models for Vietnamese Named Entity Recognition: Word-level vs. Character-level.”, July 2017. |
Phạm Thị Huyền, Nguyễn Văn Vương, Nguyễn Quý Khang, Đào Tuấn Hùng - Viện 10, Bộ Tư Lệnh 86