
Deepfake: Thách thức nghiêm trọng cho an toàn thông tin kỹ thuật số (phần 2)

QUÁ TRÌNH PHÁT TRIỂN CỦA DEEPFAKE
Đồ họa máy tính đã sử dụng các kỹ thuật chỉnh sửa video trong nhiều năm, chúng thường sử dụng các bản dựng lại 3D về hình dạng khuôn mặt của video. Hai khía cạnh cần tập trung vào trong lĩnh vực nghiên cứu tạo Deepfake là phương pháp tạo và tập dữ liệu. Deepfake là công nghệ sử dụng GAN để tạo ra nội dung giả. Tất cả các nhóm nghiên cứu làm việc trên GAN đều hướng đến mục tiêu cải thiện chất lượng ứng dụng của họ về mặt chất lượng hình ảnh và video. Các nhà nghiên cứu đã chứng minh rằng, các phương pháp tổng hợp dựa trên GAN có thể tạo ra các video giả với chất lượng cao ngoài mong đợi. Tính đến nay, việc chỉnh sửa video và hình ảnh đang ngày càng trở nên phổ biến hơn, chủ yếu là do những tiến bộ công nghệ trong học máy và học sâu.
Deepfake và AI
Deepfake tận dụng sức mạnh của AI để chỉnh sửa hoặc tạo ra nội dung hình ảnh và âm thanh có độ chân thực cao, có thể đánh lừa người xem. Một số nhà nghiên cứu đã tìm hiểu các phương pháp thị giác máy tính trong các lĩnh vực liên quan đến việc tạo ra Deepfake, bao gồm các mô hình và kiến trúc mạng nơron, trong đó phải kể đến mô hình GAN do Goodfellow và cộng sự đưa ra năm 2014. Nó chứa 2 mạng nơron riêng biệt, 1 mạng nơron đóng vai trò sinh dữ liệu (Generator) và 1 mạng nơron khác đóng vai trò phân biệt (Discriminator).
Đầu tiên, bộ phận sinh dữ liệu tạo ra các hình ảnh ngẫu nhiên, bộ phận phân biệt sẽ đánh giá những hình ảnh đó và cho bộ phận sinh dữ liệu biết mức độ chân thực của các hình ảnh được tạo ra. Tính đến nay, mô hình GAN đã được thay đổi và cải tiến rất nhiều so với phiên bản đầu tiên. Việc sử dụng mô hình mạng đối nghịch tạo sinh đào tạo trước (Pretrained GAN) để thay thế khuôn mặt người trong hình ảnh hoặc video ngày càng trở nên phổ biến và dễ dàng hơn. Với ứng dụng dựa trên giao diện đồ họa người dùng (Graphical user interface – GUI) như Fake-App, ngay cả người dùng không am hiểu về kỹ thuật cũng có thể dễ dàng tạo ra những video Deepfake.
Phân loại Deepfake
Các kỹ thuật tạo ra nội dung giả mạo được phân loại thành phương pháp truyền thống và phương pháp dựa trên học sâu. Cả hai phương pháp này đều yêu cầu các công cụ phải tạo ra những nội dung giả mạo có tính thuyết phục cao.
Phương pháp truyền thống tạo phương tiện truyền thông giả mạo
Các phương pháp truyền thống để tạo ra hình ảnh và video giả thường dựa vào các thuật toán xử lý hình ảnh và thị giác máy tính. Do các phương pháp này được phát triển trước khi kỹ thuật học sâu ra đời, nên những nội dung giả do các phương pháp này tạo ra sẽ không chân thực bằng phương pháp dựa trên học sâu. Các thuật toán tạo phương tiện giả truyền thống này được phân thành 04 loại dựa trên mục đích sử dụng của chúng: giả mạo toàn bộ khuôn mặt, sửa đổi thuộc tính, hoán đổi danh tính và hoán đổi biểu cảm/tái hiện khuôn mặt.
- Giả mạo toàn bộ khuôn mặt: Phương pháp này liên quan đến việc tạo ra khuôn mặt của một người không hề tồn tại. Biến dạng hình ảnh và biến đổi hình ảnh là hai phương pháp có thể được sử dụng để đạt được mục đích này.
- Sửa đổi thuộc tính: là việc sửa đổi một số đặc điểm của hình ảnh hoặc video. Deepfake sử dụng các sửa đổi thuộc tính cụ thể để tạo ra các bản sao giống với bản thật. Các sửa đổi này có thể là những thay đổi về hành vi, giao diện hoặc nội dung.
- Hoán đổi danh tính: là phương pháp ghép khuôn mặt của một người này lên cơ thể của một người khác. Mô hình Mạng thần kinh tích chập (Convolutional Neural Network –CNN) là một trong những mô hình được ứng dụng cho phương pháp này.
- Hoán đổi biểu cảm/tái hiện khuôn mặt: mục đích của phương pháp này là bắt chước biểu cảm của người khác. Biểu cảm khuôn mặt của một người trong hình ảnh hoặc video mục tiêu được hoán đổi với biểu cảm của một người khác trong hình ảnh hoặc video ban đầu.
Các phương pháp dựa trên kỹ thuật học sâu
Các kỹ thuật tạo ra nội dung giả dựa trên kỹ thuật học sâu đã cách mạng hóa lĩnh vực Deepfake. Các kỹ thuật này tạo ra nội dung giả bằng cách sử dụng mạng nơron tinh vi và bộ dữ liệu mở rộng, khiến cho việc tạo ra nội dung giả mạo giống thật và có tính thuyết phục cao trở nên đơn giản hơn nhiều.
- Autoencoders: Các mạng nơron này cố gắng tái tạo dữ liệu đầu vào sao cho giống nhất có thể. Trong bối cảnh Deepfake, chúng có thể mã hóa (encode) và giải mã (decode) các đặc điểm khuôn mặt để hoán đổi hoặc chỉnh sửa khuôn mặt.
- Variational Autoencoders (VAE): Đây là phần cải tiến của autoencoder dựa trên phân phối chuẩn nhiều chiều trong không gian ẩn. VAE kết hợp các tính năng tốt nhất của autoencoder và mạng nơron.
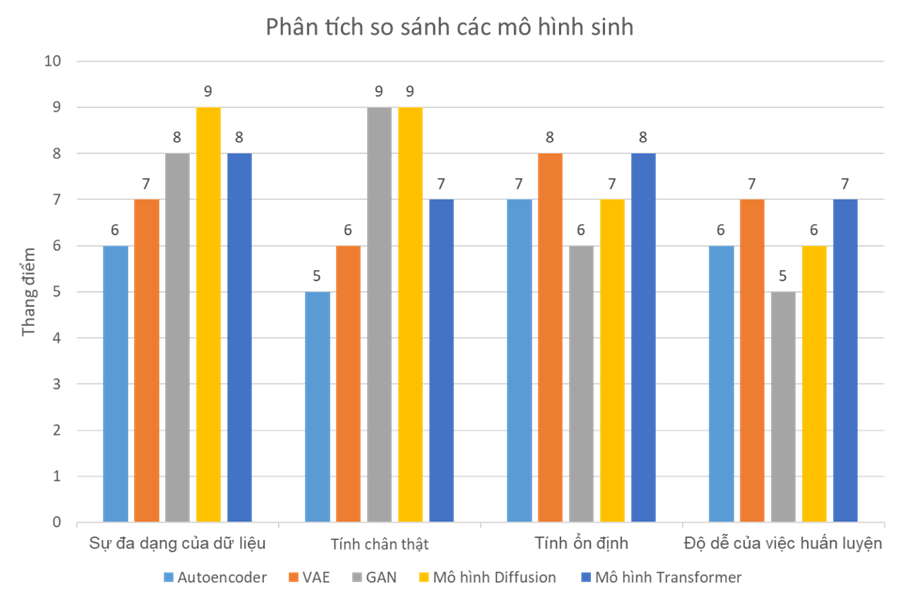
Hình 2. So sánh Autoencoder, VAE, GAN, mô hình Diffusion và mô hình Transformer về sự đa dạng của dữ liệu, tính chân thực, tính ổn định và độ dễ của việc huấn luyện chúng khi tạo nội dung Deepfake
- Mạng đối nghịch tạo sinh: GAN bao gồm 2 mạng nơron riêng biệt được gọi là bộ phận sinh dữ liệu và bộ phận phân biệt. Trong đó, bộ phận sinh dữ liệu cố gắng tạo ra nội dung giả mạo giống thật nhất còn bộ phận phân biệt sẽ cố gắng xác định sự khác biệt giữa nội dung thật và giả.
- Transformer là một mô hình học sâu được thiết kế để phục vụ giải quyết nhiều bài toán trong xử lý ngôn ngữ và tiếng nói. Mô hình này được thiết kế dựa trên cơ chế self-attention với hai phần là giải mã và mã hóa. Trong đó, cơ chế self-attention giúp phần mã hóa nhìn vào các từ khác trong lúc mã hóa một từ cụ thể, điều này giúp cho Transformers có thể hiểu được sự liên quan giữa các từ trong một câu, kể cả khi chúng có khoảng cách xa. Transformers tạo ra các hình ảnh, video Deepfake bằng cách tinh chỉnh mô hình transformer được huấn luyện trước (Pre-trained) trên một tập dữ liệu cụ thể. Mô hình có thể được sử dụng để tạo ra những nội dung phản hồi, dựa trên ngữ cảnh giống như việc con người đang nói chuyện với nhau. Một trong những ứng dụng nổi bật của mô hình Transformer là GPT của OpenAI.
- Mô hình Diffusion: là một loại mô hình tạo sinh trong học máy, có khả năng tạo ra dữ liệu mới, chẳng hạn như hình ảnh hoặc âm thanh, bằng cách bắt chước dữ liệu mà chúng đã được đào tạo. Với cách tiếp cận này, mô hình dần dần thêm nhiễu vào dữ liệu và sau đó học cách điều chỉnh để tái tạo lại dữ liệu chuẩn ban đầu. Mô hình Diffusioncó thể tạo ra hình ảnh giống thật hơn so với GAN và VAE. Ngoài ra, bộ dữ liệu DeepFakeFace (DFF) là bộ dữ liệu mã nguồn mở về hình ảnh người nổi tiếng nhân tạo được tạo bằng mô hình Diffusion.
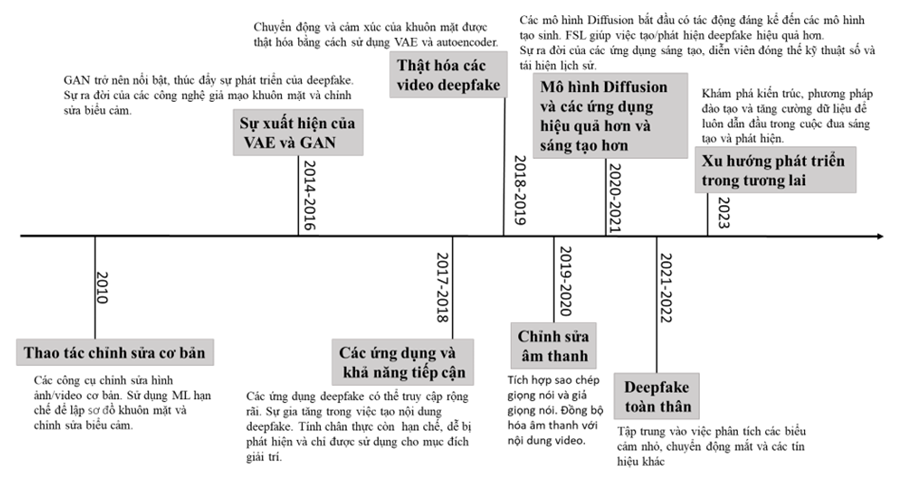
Hình 3. Dòng thời gian về sự phát triển của công nghệ Deepfake
CÁC BỘ DỮ LIỆU SỬ DỤNG ĐỂ PHÁT HIỆN DEEPFAKE HIỆN NAY
Sự phát triển nhanh chóng và mạnh mẽ của Deepfake khiến cho nhu cầu về các kỹ thuật phát hiện Deepfake ngày một tăng lên. Để các thuật toán phát hiện DeepFake có hiệu quả thì chúng cần phải được đào tạo và kiểm thử. Do đó, việc thiếu các tập dữ liệu Deepfake hoặc các tập dữ liệu Deepfake bị phân mảnh là một trở ngại đáng kể đối với việc phát hiện Deepfake. Nhiều tập dữ liệu khác nhau dùng để nghiên cứu và kiểm thử liên quan đến Deepfake hiện đã được công khai.
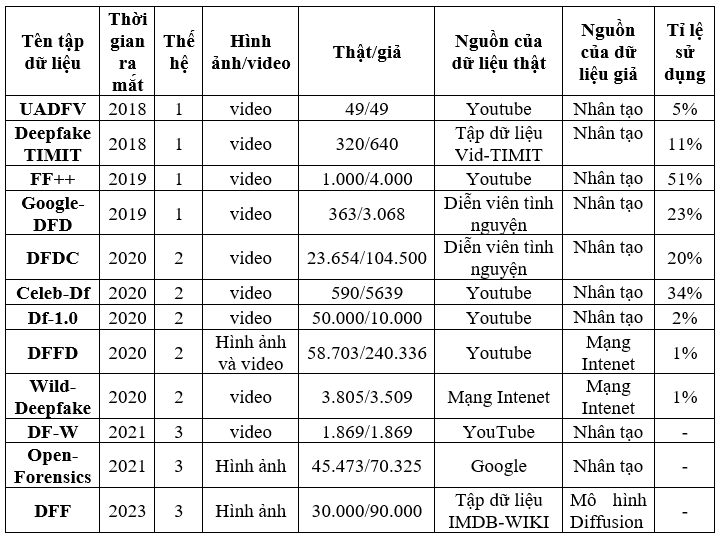
Căn cứ vào thời gian ra mắt, các tập dữ liệu được chia thành 03 thế hệ khác nhau: Các tập dữ liệu thuộc thế hệ đầu tiên chỉ chứa ít hơn 1.000 video mẫu với chỉ 1 triệu khung hình. Điều cần lưu ý là các video này thường được thu thập từ Youtube nên không thuộc về cơ sở dữ liệu hợp pháp. Các tập dữ liệu thế hệ thứ hai đã tăng số lượng video lên khoảng 10.000 video, với 1-10 triệu khung hình, ngoài ra, chất lượng của video cũng cao hơn so với các tập dữ liệu thế hệ đầu tiên. Các tập dữ liệu ra mắt gần đây được xếp vào thế hệ thứ ba với hơn 100.000 video, trong đó chứa các nhân vật có danh tính khác nhau và các kỹ thuật Deepfacke được áp dụng trên từng mẫu. Hơn nữa, các tập dữ liệu này còn cập nhật những hình ảnh tạo bởi các diễn viên được thuê để tạo mẫu trong các khung hình khác nhau nhằm tăng độ khó.
Tập dữ liệu UADFV: được phát triển tại Đại học Albany, thuộc hệ thống State University of New York (SUNY), Hoa Kỳ với mục đích hỗ trợ phát hiện Deepfake thông qua các thông tin về sinh trắc học. Thông thường, các thông tin này bao gồm biểu cảm khuôn mặt, chuyển động môi…. Tuy nhiên, UADFV lại chỉ tập trung vào tín hiệu chớp mắt. Tập dữ liệu này chứa 98 mẫu: 49 video thật được thu thập từ Youtube và 49 video giả được xử lý bằng FakeApp. Mỗi video có độ dài trung bình là 11 giây với độ phân giải là 294x500 pixel.
Tập dữ liệu Deepfake TIMIT: được phát triển dựa trên nền tảng của tập dữ liệu VidTIMIT, bao gồm 640 video dựa trên 10 chuỗi hình ảnh gốc của 32 người. Các video được tạo bằng kỹ thuật hoán đổi khuôn mặt, liên quan đến thuật toán GAN. Ngoài ra, tập dữ liệu này còn chứa hình ảnh của những người có ngoại hình tương tự nhau. Tập dữ liệu được chia làm 2 nhóm: nhóm 1 chứa 320 video chất lượng thấp có độ phân giải 64x64 với 200 khung hình. Nhóm 2 chứa 320 video chất lượng cao có độ phân giải 120x120 với 400 khung hình.
Face Forensics++ (FF++): Đây là phần mở rộng của bộ dữ liệu Face Forensics gốc. Bộ dữ liệu bao gồm các video được tạo bằng 04 phương pháp chỉnh sửa khác nhau: DeepFakes, Face2Face, FaceSwap và NeuralTextures. Những video này được tạo ra từ các mức chỉnh sửa khác nhau, giúp đánh giá hiệu suất của các phương pháp phát hiện Deepfake trong các tình huống khác nhau. Face Forensics++ thường được sử dụng trong nghiên cứu để phát hiện Deepfake và pháp y khuôn mặt.
Google-DFD (Google Deepfake Detection): Tập dữ liệu bao gồm các nhãn nhị phân cho biết mỗi video là thật hay đã bị chỉnh sửa. Cộng đồng nghiên cứu sử dụng tập dữ liệu Google-DFD để tạo và thử nghiệm các thuật toán phát hiện Deepfake.
Celeb-Df: Tập dữ liệu này được tạo ra vào tháng 11/2019 và được đặt tên theo tập dữ liệu CelebA, một tập dữ liệu nhận dạng khuôn mặt phổ biến. Tập dữ liệu này cũng bao gồm một tập hợp các chú thích không gian và thời gian, cung cấp thông tin về các vùng chỉnh sửa và các cấp độ chỉnh sửa. Đây là một trong những tập dữ liệu được sử dụng rộng rãi trong nghiên cứu phát hiện Deepfake.
DeeperForensics-1.0: còn được gọi là DeepFake 1.0, là một tập dữ liệu các video đã được chỉnh sửa. Các mức độ thao túng trong các video khác nhau nhằm đánh giá hiệu quả của các phương pháp phát hiện Deepfake trong các tình huống khác nhau.
DeepFake Detection Challenge (DFDC): Đây là tập dữ liệu quy mô lớn gồm các video và hình ảnh đã qua chỉnh sửa được tạo ra cho Cuộc thi Phát hiện DeepFake (DeepFake Detection Challenge) do Facebook tổ chức vào năm 2020.
Wild-Deepfake: là bộ dữ liệu phát hiện Deepfake được tạo ra vào năm 2020. Wild-Deepfake được sử dụng rộng rãi trong cộng đồng nghiên cứu trong việc phát triển các thuật toán phát hiện deepfake.
DF-W: là một tập dữu liệu mở dùng để đánh giá hiệu suất của các hệ thống nhận dạng khuôn mặt khi có sự can thiệp của Deepfake.
OpenForensics: Đây là một tập dữ liệu nguồn mở, cung cấp miễn phí cho cộng đồng nghiên cứu, được dùng để phát triển và thử nghiệm các thuật toán phát hiện Deepfake.
DeepFakeFace: Bộ dữ liệu DFF bao gồm từ 120.000 - 30.000 hình ảnh thật và 90.000 hình ảnh giả. Bộ dữ liệu sử dụng hình ảnh thật từ bộ dữ liệu IMDB-WIKI để thử nghiệm các phương pháp phát hiện trong nhiều giao diện và cài đặt khác nhau.
Bảng 2. Bảng tóm tắt các tập dữ liệu Deepfake từ năm 2018 đến năm 2023
LỜI KẾT
Deepfake mặc dù mang lại nhiều lợi ích, tuy nhiên nó cũng tiềm ẩn nhiều nguy cơ rủi ro đối với an toàn thông tin. Sự phát triển nhanh chóng của các công cụ và kỹ thuật Deepfake yêu cầu người dùng phải liên tục nâng cao nhận thức và triển khai các biện pháp phòng chống hiệu quả. Việc nghiên cứu và hiểu rõ các yếu tố liên quan đến Deepfake không chỉ giúp phát hiện và ngăn chặn các mối đe dọa mà còn hỗ trợ trong việc xây dựng các giải pháp bảo mật toàn diện nhằm bảo vệ thông tin và uy tín cá nhân. Bài báo này không chỉ cung cấp một cái nhìn sâu rộng về công nghệ Deepfake, từ khái niệm cơ bản đến sự phát triển, phân loại, cách thực hiện và các bộ dữ liệu hiện có mà còn nhấn mạnh sự cần thiết phải tiếp tục nghiên cứu và phát triển các chiến lược đối phó hiệu quả trong bối cảnh ngày càng nhiều thách thức an ninh mạng.
ThS. Đồng Thị Thùy Linh, Học viện Kỹ thuật mật mã



















