Phương pháp phân tích Entropy để phát hiện che giấu mã độc
1. Kỹ thuật đóng gói để che giấu mã độc
Ban đầu, kỹ thuật đóng gói được phát triển nhằm tối ưu hóa bộ nhớ và băng thông trong quá trình lưu trữ và truyền tệp tin. Thuật toán sử dụng trong kỹ thuật đóng gói trở thành công cụ được kẻ viết mã độc cải tiến để tránh bị phát hiện. Kỹ thuật đóng gói (bao gồm kỹ thuật nén và mã hóa) với mục đích che giấu mã độc thường được sử dụng để chuyển đổi mã thực thi nhị phân sang một định dạng khác nhằm thu gọn mã độc và làm biến dạng khác biệt hẳn so với ban đầu, tránh sự phát hiện của các chương trình diệt virus dựa trên cơ sở mẫu nhận dạng. Trong nhiều trường hợp, mã độc hại được tổ hợp đệ quy từ các kỹ thuật nén và mã hóa khác nhau, để cùng một mã độc nhưng có thể nhanh chóng tạo ra một lượng lớn biến thể nhị phân thực thi nhằm phát tán.
Đoạn mã thực thi được xây dựng với hai phần chính trong quy trình đóng gói, gồm hai giai đoạn. Giai đoạn 1, đoạn mã thực thi gốc được nén và lưu giữ trong tệp thực thi nén như dữ liệu thông thường. Giai đoạn 2, môđun giải nén được thêm vào tệp thực thi nén và sẽ được sử dụng để phục hồi đoạn mã gốc.
Quá trình mở gói thực hiện theo các bước có thứ tự ngược lại với quá trình đóng gói. Môđun giải nén trước tiên được thực hiện và đoạn mã thực thi nhảy đến câu lệnh thực thi đầu tiên của mã giải nén. Sau khi phục hồi đoạn mã thực thi gốc, con trỏ lệnh thực thi sẽ nhảy ra khỏi câu lệnh cuối cùng của môđun giải nén để nhảy đến điểm vào (entry point) của đoạn mã thực thi.
Kỹ thuật đóng gói xuất hiện trong phần lớn các mẫu mã độc hại, tạo ra thách thức lớn cho người phân tích mã, đặc biệt là khi sử dụng phương pháp phân tích tĩnh để phân tích một lượng lớn mẫu mã độc hại. Bởi vì, trước khi bắt tay vào thực hiện quá trình phân tích mã độc, ta cần phải xác định đoạn mã bị mã hóa hay nén để thực hiện việc giải nén cũng như giải mã một cách nhanh chóng và hiệu quả. Do nhiều mẫu virus vẫn duy trì trạng thái mã hóa và nén, người phân tích phải xác định chúng bằng phân tích thủ công hoặc sử dụng kỹ thuật phân tích ngược (reverse engineering). Yêu cầu đặt ra là cần phải xác định nhanh chóng và chính xác đoạn mã độc nén và giải nén. Phương pháp phân tích entropy là một kỹ thuật hỗ trợ cho người phân tích mã độc giải quyết yêu cầu này.
2. Phương pháp Entropy phát hiện mã độc được nén và mã hóa
Khái niệm Entropy
Nguồn gốc khái niệm entropy đến từ khoa học nhiệt động lực học. Entropy là một đặc trưng cho độ nhiễu loạn trong một hệ thống khép kín. Năm 1948, Claude Shannon đã “mượn” khái niệm entropy để miêu tả sự ngẫu nhiên trong luồng thông tin. Điểm khác nhau cơ bản giữa entropy trong lý thuyết nhiệt động lực học và entropy trong lý thuyết thông tin là người ta không thể biết tất cả các trạng thái có thể xảy ra. Do vậy, phương pháp thống kê chỉ được sử dụng ở mức gần đúng. Trong lý thuyết thông tin, số trạng thái và khả năng các trạng thái được xác định chính xác vì nội dung của tệp tin được biết một cách chắc chắn.
Chúng ta có thể tính entropy của các sự kiện rời rạc ngẫu nhiên x sử dụng công thức sau: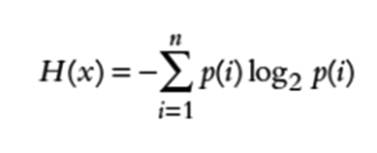
Trong đó p(i) là khả năng của khối thông tin thứ i trong chuỗi n biểu tượng của sự kiện x, n là tổng số các giá trị có thể nhận của tín hiệu.
Trong phân tích thông tin, chúng ta quan tâm đến các byte dữ liệu (mỗi byte có 256 giá trị xảy ra khác nhau). Bởi vậy, giá trị entropy của một tệp sẽ là giá trị trong khoảng từ 0 đến 8:
Phân tích Entropy phát hiện mã độc được nén hoặc mã hóa
Entropy thông tin mô tả mức độ hỗn loạn trong một tín hiệu lấy từ một sự kiện ngẫu nhiên. Nói cách khác, entropy cũng chỉ ra có bao nhiêu thông tin trong tín hiệu, với thông tin là các phần không hỗn loạn ngẫu nhiên của tín hiệu. Một tập tin được nén cũng có thể bị phát hiện nhờ kỹ thuật tính toán entropy. Các dữ liệu nén hoặc mã hóa khá giống với các dữ liệu ngẫu nhiên, do đó nó có mức entropy cao. Trong khi các dữ liệu không được mã hóa hay nén thường có mức entropy thấp. Sử dụng entropy để đo sự ngẫu nhiên và không dự đoán trước trong một chuỗi sự kiện hoặc một dãy giá trị dữ liệu là chấp nhận được về mặt thống kê trong lĩnh vực lý thuyết thông tin. Trong phân tích mã độc hại, các nhà nghiên cứu đã sử dụng một số công cụ phân tích entropy phát hiện đoạn mã độc nén và mã hóa, chẳng hạn như PEAT (Portable Executable Analysis Toolkit).
PEAT là bộ công cụ cho phép người phân tích kiểm tra các khía cạnh của cấu trúc tệp Window PE (Portable Executable). PEAT tính toán entropy cho mỗi đoạn PE của từng đoạn tệp. Sau đó, nó chuẩn hóa những giá trị entropy này so với entropy tổng cộng của các giai đoạn PE đã tính. Điều này giúp người phân tích xác định đoạn PE có sự thay đổi lớn giá trị entropy, từ đó xác định đoạn PE có khả năng bị sửa so với đoạn tệp nguyên bản ban đầu. Để sử dụng PEAT hiệu quả, người phân tích phải có nền tảng kiến thức về tệp PE, virus, cũng như kinh nghiệm làm việc với PEAT.
Công cụ phân tích entropy nhị phân Bintropy
Bintropy là công cụ phân tích mẫu, ước tính khả năng một tệp tin có chứa các thông tin nén hoặc mã hóa. Bintropy có hai chế độ hoạt động:
- Chế độ thứ nhất, công cụ sẽ phân tích entropy của mỗi đoạn thực thi có định dạng PE, được xác định trong phần đầu của tệp thực thi. Điều này giúp người phân tích xác định đoạn mã thực thi nào có thể bị mã hóa và nén. Một bộ biên dịch chuẩn tạo ra PE thực thi có các phần theo định dạng chuẩn (.text, .data, .reloc, .rsrc). Tuy nhiên, nhiều công cụ đóng gói biến đổi định dạng của tệp thực thi gốc, nén các đoạn mã, dữ liệu và dồn chúng vào một hay hai đoạn mới. Trong chế độ này, Bintropy tính giá trị entropy cho mỗi đoạn nó cần. Tuy nhiên, không tính entropy cho phần đầu tệp tin bởi vì phần này thường không chứa các byte dữ liệu nén hay mã hóa.
- Chế độ thứ hai hoàn toàn bỏ qua định dạng tệp, thay vào đó Bintropy phân tích entropy của toàn bộ tệp, từ byte đầu tiên cho đến byte cuối cùng. Với tệp định dạng PE, người dùng có thể phân tích entropy của đoạn mã và dữ liệu ẩn tại cuối tệp hoặc ở giữa các đoạn định dạng PE.
Entropy của một khối dữ liệu là một phép đo thống kê lượng thông tin chứa bên trong. Trong bài báo “Sử dụng phân tích entropy để tìm ra mã độc nén và mã hóa” Hamrock và Lyda đưa ra một quan sát đáng chú ý là các dữ liệu nén và mã hóa trong mẫu mã dữ liệu độc hại đóng gói có mức entropy cao. Mã chương trình và dữ liệu bình thường có mức entropy thấp hơn nhiều. Mã độc hại sử dụng kỹ thuật đóng gói được xác định bởi mức entropy cao trong nội dung của nó.
Để đánh giá khả năng công cụ Bintropy dựa trên phân tích entropy, Lynda và Hamrock đã tiến hành đánh giá thử nghiệm trên bốn tập dữ liệu với các phân loại tệp khác nhau: plain text, thực thi thông thường, thực thi nén và thực thi mã hóa. Mỗi tập dữ liệu gồm 100 tệp khác nhau, mỗi tệp được tính entropy dựa trên các khối dữ liệu có độ dài 256 byte. Công cụ Bintropy tính entropy mức trung bình của các khối và khối có mức entropy cao nhất. Mục đích thử nghiệm này là xác định mức entropy tối ưu để phân loại tệp thực thi thông thường và tệp thực thi đã biến đổi sử dụng kỹ thuật mã hóa hoặc kỹ thuật nén. Sau khi sử dụng tập dữ liệu training, Bintropy có khả năng phát hiện các tệp thực thi bị nén hoặc mã hóa khi đặc tính entropy vượt qua một mức định trước.
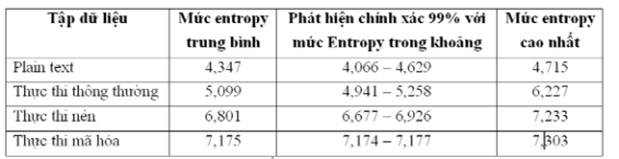
Bảng 1. Độ chính xác thống kê entropy dựa trên tập dữ liệu
Dựa trên bảng kết quả chúng ta nhận thấy, với độ chính xác đạt 99% và mức Entropy trong khoảng 6,677 đến 7,177, công cụ Bintropy sẽ phát hiện tệp nén hay mã hóa.
Lyda và Hamrock cũng đã thực hiện xác định xu hướng entropy bởi công cụ Bintropy và để tạo độ tin cậy của đánh giá đã áp dụng trên một tập 21.567 mã độc Win32 - với thực thi định dạng PE từ bộ thu thập của các hãng phần mềm chống virus nổi tiếng trên thế giới trong khoảng thời gian từ tháng 01/2000 đến tháng 12/2005. Dựa trên khảo sát bởi sử dụng công cụ Bintropy để phân tích, kết quả chỉ ra rằng, UPX1 là phần được kẻ viết mã độc sử dụng kỹ thuật đóng gói phổ biến nhất, sau đó là phần text (Hình 1).
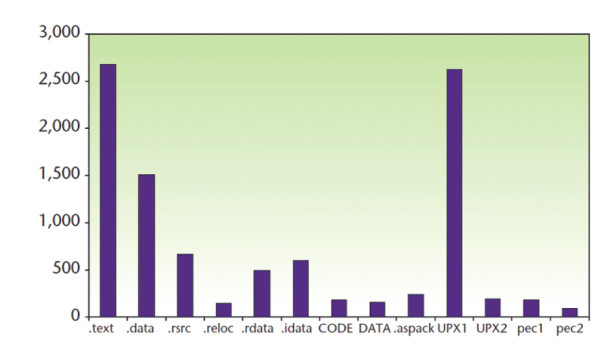
Hình 1. Phân bố số lưọng tệp mã độc theo đoạn (secsion) bị mã hóa hoặc nén, trong đó UPX1 phổ biến nhất
3. Kết luận
Ưu điểm của phương pháp phân tích entropy là đưa ra một kỹ thuật tiện dụng và nhanh chóng để phân tích một mẫu mức nhị phân và xác định vùng tệp PE khả nghi. Một khi việc phân tích xác định được phần có mức entropy bất thường, người phân tích có thể thực hiện phân tích sâu và chi tiết hơn với các công cụ kỹ thuật dịch ngược khác (reverse – engineering) chẳng hạn như IDAPro diassembler.