Phát hiện mã độc dựa vào học máy và thông tin PE Header (Phần I)
GIỚI THIỆU
Mã độc (Malware) là một trong những mối đe dọa nghiêm trọng đối với bảo mật của hệ thống máy tính, thiết bị thông minh và nhiều ứng dụng. Nó có thể gây nguy hiểm cho dữ liệu quan trọng, nhạy cảm bằng cách đánh cắp, sửa đổi, mã hoá hoặc phá hủy dữ liệu. Theo báo cáo của AV-TEST [1-3], trung bình mỗi ngày có khoảng 350.000 mã độc mới được tạo ra (Hình 1 mô tả tổng số mã độc được phát hiện từ năm 2012 đến năm 2021 (cập nhật ngày 12/03/2021) của tổ chức AV-TEST). Điều này cho thấy mã độc là vấn đề nóng, có tốc độ phát triển nhanh.
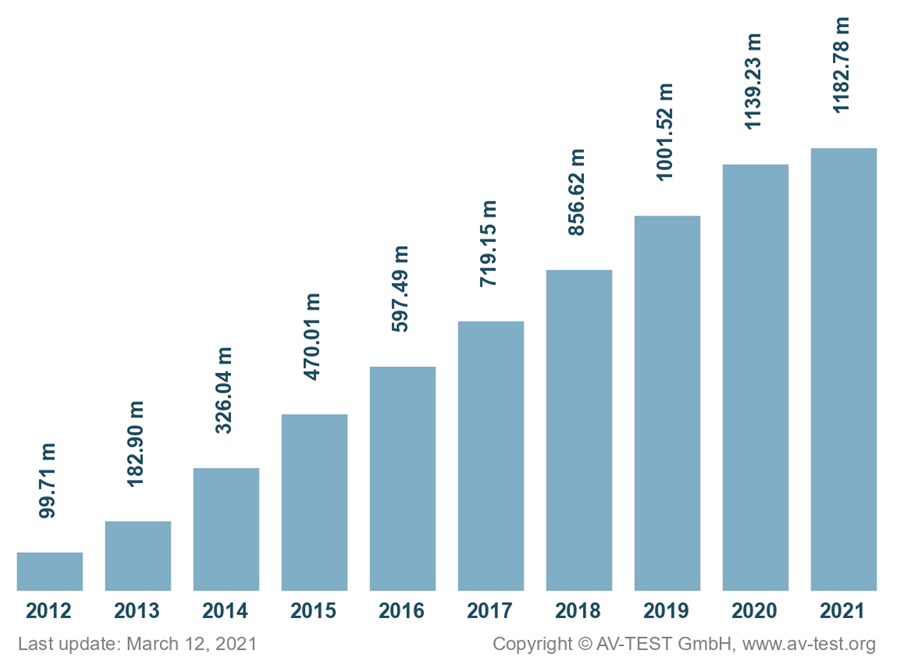
Hình 1. Tổng số mã độc được phát hiện từ năm 2012 đến đầu năm 2021 của AV-TEST
Phương pháp dựa trên dấu hiệu nhận dạng được sử dụng trong các phần mềm antivirus khó có khả năng phát hiện chính xác mã độc mới. Mặt khác, dấu hiệu nhận dạng của mã độc phải được lưu trữ trước để thực hiện so sánh mẫu. Do vậy, cần chi phí cho việc lưu trữ chữ ký và thời gian so sánh. Ngoài ra, khả năng phát hiện của phần mềm antivirus không hiệu quả với mã độc loại đa hình, biến hình, hay mã độc được sửa đổi.
Việc phát hiện và phân loại phần mềm độc hại hiệu quả có thể được thực hiện dựa trên việc phân tích tiêu đề PE (Portable Executable) Header của các tệp thực thi (EXE, DLL), kết hợp với các kỹ thuật học máy khác nhau.
Phương pháp học máy đóng một vai trò quan trọng trong việc phát hiện mã độc tự động. Nhiệm vụ thách thức nhất là chọn một bộ đặc trưng phù hợp từ một tập dữ liệu lớn để có thể xây dựng mô hình phân loại trong thời gian ngắn hơn với độ chính xác cao hơn. Mục đích của công việc này trước hết là để thử nghiệm đánh giá, xem xét tổng thể các phương pháp phân loại, phát hiện mã độc và thứ hai là phát triển một hệ thống tự động để phát hiện mã độc dựa trên PE Header các file thực thi (EXE, DLL) với độ chính xác cao và thời gian thực hiện nhanh chóng.
Trên cơ sở đó, bài báo cũng tiếp cận việc phân tích mã độc theo cấu trúc tiêu đề của file thực thi PE Header và sử dụng một số kỹ thuật học máy để phát hiện, phân loại các file mã độc với file sạch. Tuy nhiên, có điểm mới là thông tin đặc trưng PE Header được lựa chọn theo khảo sát thống kê giữa các file mã độc và file sạch. Làm thế nào để phát hiện mã độc nhanh chóng và chính xác là vấn đề được các chuyên gia quan tâm nghiên cứu.
Để thực hiện, nhóm tác giả đã thu thập một tập 5.000 file thực thi EXE đa dạng, gồm 2.500 file mã độc và 2.500 file sạch. Nhóm tác giả thực hiện phân tích các thông tin từ PE Header. Sau đó thực hiện khảo sát thống kê và lựa chọn thông tin đặc trưng quan trọng từ PE Header. Tiếp theo là áp dụng các kỹ thuật học máy khác nhau để phân loại và phát hiện mã độc. Sau cùng là tiến hành thử nghiệm, đánh giá độ chính xác và so sánh kết quả nghiên cứu so với các kết quả hiện hành.
PHÂN TÍCH CẤU TRÚC PE HEADER
Các Header của tệp tin thực thi cấu trúc PE có thể cung cấp nhiều thông tin giá trị hơn là các hàm Import. Định dạng của PE Header chứa Header và các chuỗi các Section quan trọng. Header chứa các siêu dữ liệu (Metadata) về bản thân tệp tin thực thi. Nội dung phía dưới Header là các Section thực tế, mỗi Section chứa các thông tin liên quan chức năng của tệp thực thi.
Phân tích cấu trúc định dạng PE Header
Cấu trúc dữ liệu PE Header [4] được thiết kế bởi Microsoft từ năm 1993, dành cho các file thực thi EXE và thư viện liên kết động DLL trên Windows.
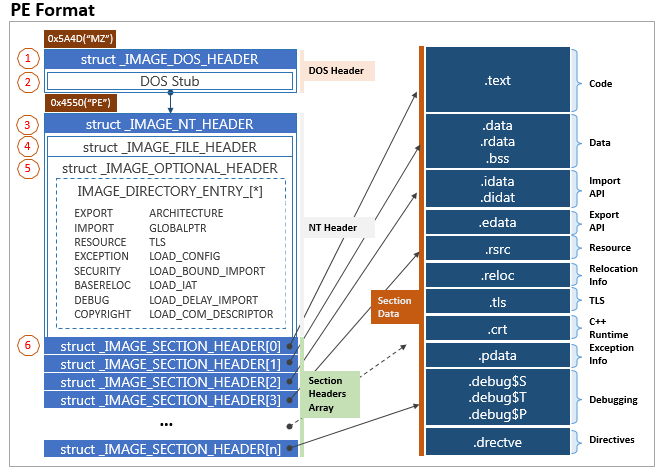
Hình 2. Cấu trúc định dạng PE Header [5]
Cấu trúc dữ liệu PE Header [5] được mô tả như Hình 2, trong đó:
(1) DOS Header: Tất cả các file PE được bắt đầu với DOS Header có kích thước 64 byte, trong đó 4 byte cuối mô tả định vị điểm bắt đầu phần NT Header. Phần này được định nghĩa như một cấu trúc IMAGE_DOS_HEADER. Dấu hiệu nhận biết các file thực thi EXE/DLL là 2 byte đầu tiên 0x5A4D (“MZ”). Nếu file được thực thi trong hệ điều hành DOS thì DOS Header có thể xác định nó như một file thực thi hợp lệ. Phần DOS Header kiểm tra thực tế khi một file thực thi hợp lệ.
(2) MS-DOS Stub: Sau DOS Header là phần MS-DOS Stub. Hiện nay, phần này được biên dịch chỉ để xuất ra thông báo “This program cannot be run in DOS mode”.
(3) PE Header (NT Header): được mô tả một cấu trúc IMAGE_NT_HEADERS, gồm 3 trường chính: PE-Signature, File Header và Optional Header.
(4) File Header: được xem như cấu trúc IMAGE_FILE_HEADER.
(5) Optional Header: được xem như cấu trúc IMAGE_OPTIONAL_HEADER.
(6) Section Table (Section Headers): gồm một mảng các cấu trúc IMAGE_SECTION_HEADER.
Kiểm tra tệp tin thực thi với công cụ PEView
Phần PE Header lưu trữ thông tin quan trọng của tệp tin thực thi. Ta có thể sử dụng công cụ PE Explorer hay PEView để xem các thông tin này như minh hoạ ở Hình 3.
Trên Hình 3, ta thấy phần được chọn là IMAGE_FILE_HEADER, hai phần đầu thuộc về quá khứ là IMAGE_DOS_HEADER và MS-DOS Stub Program. Qua phân tích khảo sát thống kê, cấu trúc IMAGE_DOS_HEADER có thể có thông tin liên quan đến mã độc.
Kế tiếp là IMAGE_NT_HEADER, cho thấy Header của NT (PE). Chữ ký không đổi (“PE”) có thể bỏ qua. Mục IMAGE_FILE_HEADER được chọn và hiển thị nội dung ở cửa sổ bên phải chứa các thông tin cơ bản về tệp tin này. Tại trường Description, tiểu mục Time Date Stamp cho ta biết thời điểm biên dịch tệp tin này. Thông tin này khá quan trọng, nếu thời điểm biên dịch là cũ (19/6/2008) so với hiện tại, ta có thể dùng các chương trình antivirus để dò quét, phát hiện bằng dấu hiệu và tiêu diệt; nếu thời điểm biên dịch là mới thì cần phải phân tích thêm.
Phần IMAGE_OPTIONAL_HEADER bao gồm một số thông tin quan trọng. Các mô tả của hệ thống con (Subsystems) chỉ ra là giao diện dòng lệnh (Console) hay đồ hoạ (GUI) của chương trình: kiểu Console chạy trong cửa sổ dòng lệnh của Windows có giá trị IMAGE_ SUBSYSTEM_CUI; kiểu GUI chạy trong môi trường đồ hoạ của Windows có giá trị IMAGE_ SUBSYSTEM_GUI.
Các thông tin khác từ Section Table, gồm mảng các cấu trúc IMAGE_SECTION_HEADER như: .text, .data, .rdata, .bss, .idata, .didat, .edata, .rsrc,...
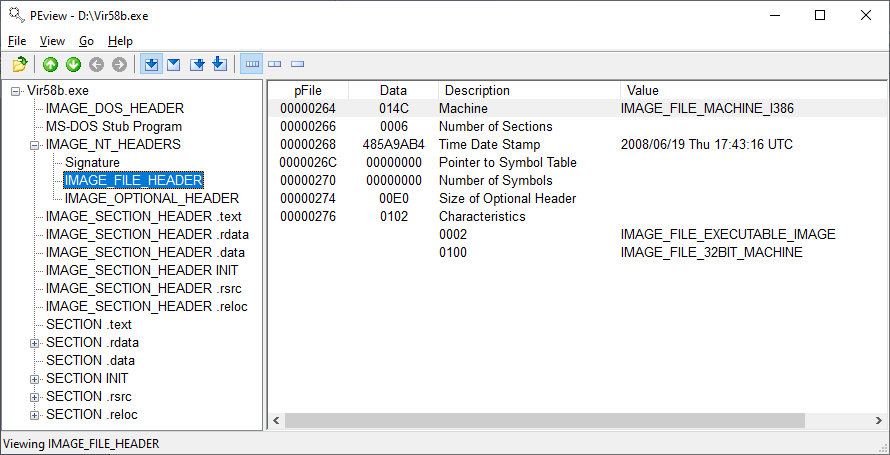
Hình 3. PEView với tệp Vir58b.exe tại mục IMAGE_FILE_HEADER
KHẢO SÁT VÀ LỰA CHỌN ĐẶC TRƯNG
Mục tiêu của phần này là khảo sát thống kê, trích chọn tập đặc trưng quan trọng từ PE Header. Tập đặc trưng này sẽ được thử nghiệm với một số mô hình học máy tiêu biểu như Mô hình NB (Naive Bayes), Mạng Nơ-ron nhân tạo ANN (Artificial Neural Network), Cây quyết định DT (Decision Tree) và Rừng ngẫu nhiên RF (Random Forest) nhằm thử nghiệm phát hiện mã độc.
Quy trình thực hiện như sau:
Bước 1: Thu thập các mẫu file thực thi (*.EXE) để thống kê so sánh PE Header, bao gồm 5.000 file trong đó có 2.500 file sạch và 2.500 file mã độc.
Bước 2: Thực hiện tiền xử lý dữ liệu với các kỹ thuật: đọc các bộ đặc trưng DOS Header, File Header, Optional Header từ PE Header của các file sạch và các file mã độc.
Bước 3: Khảo sát thống kê đặc trưng PE Header qua đồ thị để trích chọn ra tập đặc trưng rút gọn. Để dùng cho huấn luyện và thử nghiệm, tác giả thêm một nhãn class gán cho phân lớp ở cuối mỗi bản ghi tập đặc trưng: class = 1 ứng với bản ghi của file mã độc; class = 0 ứng với bản ghi của file sạch.
Để thống kê, ta tạo tập dữ liệu khảo sát: thực hiện liệt kê toàn bộ 2.500 bản ghi các đặc trưng PE Header của file sạch trước và ghép với 2.500 bản ghi các đặc trưng PE Header của file mã độc sau.
Tập đặc trưng từ cấu trúc PE Header
Trong phạm vi bài báo, chọn 3 cấu trúc trong PE Header gồm 55 đặc trưng (Tập 1, gốc).
a) IMAGE_DOS_HEADER: 19 đặc trưng.
b) IMAGE_FILE_HEADER: 7 đặc trưng.
c) IMAGE_OPTIONAL_HEADER: 29 đặc trưng.
Khảo sát thống kê và lựa chọn đặc trưng cho các mô hình học máy
Tiến hành phân tích, thống kê toàn bộ tập dữ liệu khảo sát với 5.000 bản ghi (2.500 bản ghi đầu là sạch, 2.500 bản ghi sau là mã độc) để trích chọn đặc trưng từ 55 đặc trưng gốc. Trong đó, lựa chọn các đặc trưng có giá trị phân biệt giữa mã độc và file sạch cao, còn các đặc trưng có giá trị phân biệt thấp hoặc không đổi cần loại bỏ.
a) Thống kê lựa chọn trong 19 đặc trưng của IMAGE_DOS_HEADER:
Hai đặc trưng e_cparhdr và e_sp tương quan chặt với nhau trên toàn bộ tập dữ liệu, cho phép phân biệt giữa file sạch và mã độc. Do vậy ta chỉ cần chọn 1 là đủ (e_sp).
+ Chọn 2 đặc trưng có giá trị phân biệt cao trên đồ thị nửa đầu (file sạch) và nửa cuối (mã độc) là e_sp và e_lfanew (xem các Hình 4a, 4b).
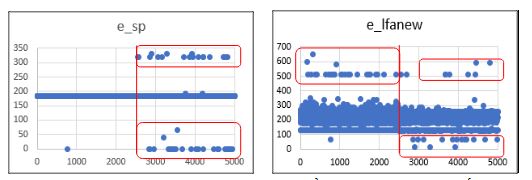
Hình 4a. Đặc trưng s_sp Hình 4b. Đặc trưng e_lfanew
+ Các đặc trưng còn lại có giá trị phân biệt kém hoặc không đổi, cần loại bỏ (xem các Hình 5a, 5b).
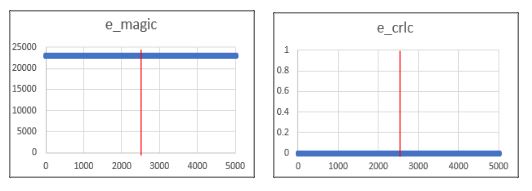
Hình 5a. Đặc trưng e_magic có giá trị không đổi Hình 5b. Đặc trưng e_crlc có giá trị không đổi
b) Khảo sát thống kê lựa chọn trong 07 đặc trưng của IMAGE_FILE_HEADER: Bằng cách khảo sát tương tự như mục (a):
+ Chọn 02 đặc trưng có giá trị phân biệt cao là NumberOfSections và Characteristics (xem các Hình 6a, 6b).
+ Số các đặc trưng còn lại có giá trị phân biệt kém hoặc không đổi, cần loại bỏ.
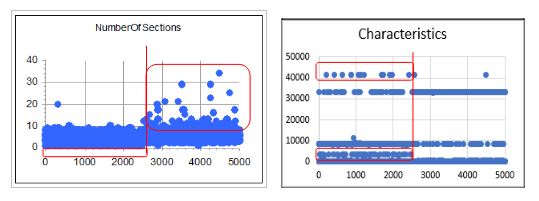
Hình 6a. Đặc trưng NumberOfSections Hình 6b. Đặc trưng Characteristics
c) Khảo sát thống kê lựa chọn trong 29 đặc trưng của IMAGE_OPTIONAL_HEADER: Cũng bằng cách thống kê tương tự như các mục (a), (b) ta thu được:
+ Chọn 10 đặc trưng có giá trị phân biệt cao giữa nửa đầu (file sạch) và nửa cuối (mã độc) gồm: MinorLinkerVersion, MajorOperatingSystemVersion, SizeOfUninitializedData, MajorSubsystemVersion, AddressOfEntryPoint, ImageBase, CheckSum, Subsystem, DllCharacteristics, SizeOfStackReserve (xem các Hình 7a, 7b).
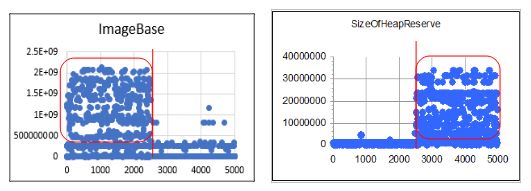
Hình 7a. Đặc trưng ImageBase Hình 7b. Đặc trưng SizeOfStackReserve
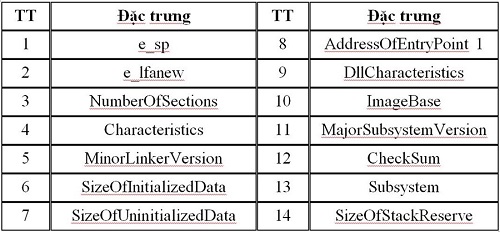
+ Số các đặc trưng còn lại có giá trị phân biệt kém hoặc không đổi, cần loại bỏ. Cuối cùng, sau khi phân tích thống kê, ta trích chọn được 14 đặc trưng (Bảng 1).
Bảng 1. Mô tả 14 đặc trưng rút gọn (Tập 2)
KẾT LUẬN
Thông qua phân tích, khảo sát thống kê tác giả đã trích chọn được 14 đặc trưng quan trọng có giá trị phân biệt cao, loại bỏ các đặc trưng dư thừa có giá trị phân biệt thấp, không đổi hoặc tương tự nhau. Điều đó sẽ làm giảm kích thước tập đặc trưng và làm giảm thời gian tính toán nhưng vẫn đảm bảo độ chính xác cao khi áp dụng các mô hình học máy để phát hiện file sạch hay mã độc.
(Kỳ tiếp theo: Thử nghiệm một số mô hình học máy với các tập đặc trưng từ PE Header cho phát hiện mã độc).
Trần Ngọc Anh (Bộ tư lệnh 86), Võ Khương Lĩnh (Đại học Nguyễn Huệ)