Web scraping mối đe dọa phổ biến nhưng chưa được quan tâm đúng mức
Web scraping là gì?
Web scraping là quá trình tự động thu thập thông tin từ web, đây là loại tấn công nhằm mục đích sao chép hoặc lấy cắp nội dung web để sử dụng ở nơi khác. Việc tái sử dụng nội dung này có thể được chủ sở hữu trang web chấp thuận hoặc không.
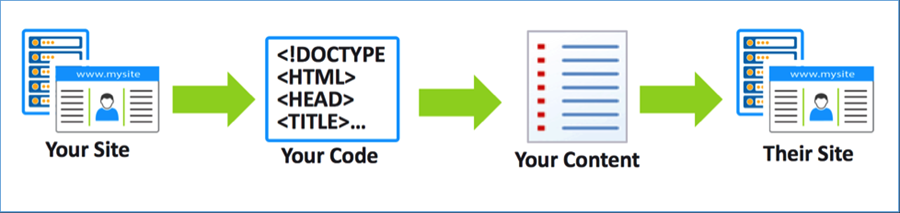
Hình 1. Bot thu thập thông tin trên website để sử dụng lại
Thông thường, tin tặc thực hiện điều này bằng cách sử dụng bot để truy cập mã nguồn của trang web và sau đó phân tích cú pháp để thu thập các dữ liệu quan trọng mà chúng muốn. Sau khi lấy được dữ liệu, chúng thường đăng nội dung đó ở một trang web khác (Hình 1).
Một loại thu thập thông tin từ web cao cấp hơn là thu thập thông tin từ cơ sở dữ liệu (database scraping). Kiểu thu thập này cũng tương tự như thu thập thông tin từ trang web nhưng điểm khác biệt là tin tặc tạo ra bot tương tác với ứng dụng web để thu thập thông tin từ cơ sở dữ liệu của trang web (Hình 2).
Một ví dụ của thu thập thông tin từ cơ sở dữ liệu là khi bot nhắm vào một trang web bảo hiểm để lấy báo giá cho các trường hợp bảo hiểm khác nhau. Bot sẽ thử tất cả các kết hợp có thể có trong ứng dụng web để nhận báo giá cho tất cả các tình huống. Trong một ví dụ khác như truy cập trang web cho thuê xe ô tô, bot tương tác với ứng dụng rằng nó đang tìm kiếm báo giá cho một chiếc xe Honda, sau đó là cho một chiếc Toyota, rồi một chiếc Ferrari... Mỗi lần bot sẽ nhận được một kết quả khác nhau từ ứng dụng. Thử đủ số lần, có thể lấy được toàn bộ tập dữ liệu.
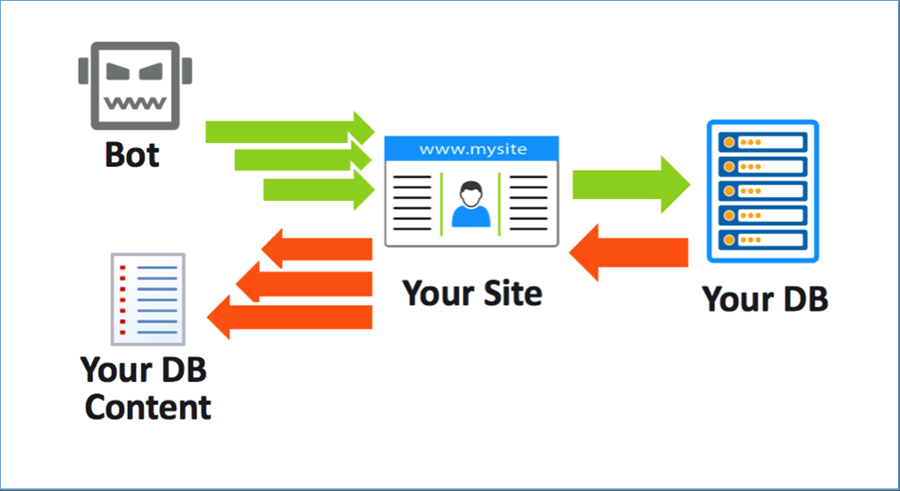
Hình 2. Bot tương tác với ứng dụng web để lấy thông tin từ cơ sở dữ liệu
Thu thập thông tin từ cơ sở dữ liệu có thể được sử dụng để ăn cắp sở hữu trí tuệ, bảng giá, danh sách khách hàng, giá bảo hiểm và các bộ dữ liệu khác. Hãy xem xét trường hợp của một đại lý xe hơi cho thuê, nếu một công ty tạo ra một bot thường xuyên kiểm tra giá của đối thủ cạnh tranh và giảm nhẹ tất cả các mức giá của mình, thì công ty đó sẽ có lợi thế cạnh tranh. Mức giá thấp hơn này sẽ xuất hiện trong tất cả các trang web tổng hợp so sánh cả hai công ty và có khả năng dẫn đến nhiều khách thuê xe hơn và xếp hạng cao hơn trong công cụ tìm kiếm (Hình 3).
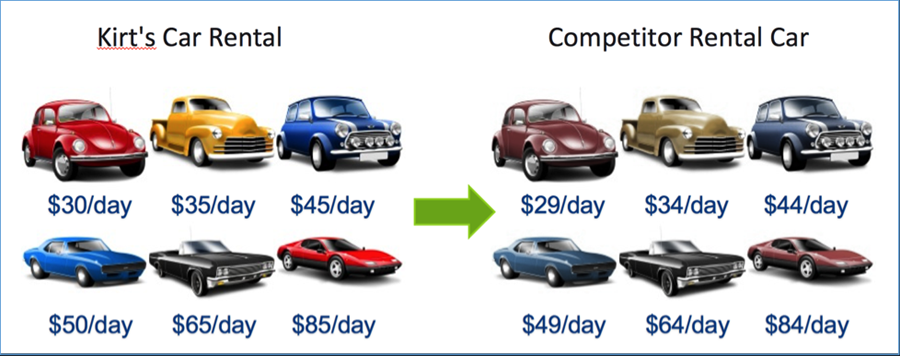
Hình 3. Sau khi dùng bot thu thập giá thuê xe, đối thủ chào mức giá thấp hơn để cạnh tranh
Một kiểu thu thập thông tin từ web trái phép khác không kém phần nguy hiểm là thu thập thông tin khách hàng, chẳng hạn như lợi dụng API để lấy ID và số điện thoại của người dùng Facebook. Chuyên gia bảo mật Bob Diachenko, người phát hiện thông tin của gần 300 triệu người dùng Facbook bị rò rỉ trên mạng hồi tháng 3/2020 cho rằng, tội phạm thu thập những thông tin đó bằng cách lợi dụng API của chính Facebook. Tuy hoạt động thu thập thông tin kiểu này không cạnh tranh trực tiếp với chủ website nhưng việc để lộ thông tin khách hàng đôi khi còn dẫn đến hậu quả nghiêm trọng hơn những kiểu thu thập thông tin sản phẩm hay giá bán.
Vì các website thường yêu cầu khách tạo tài khoản trước khi thực hiện việc lấy báo giá hay mua hàng và chặn những tài khoản, địa chỉ gửi quá nhiều yêu cầu trong một thời gian ngắn. Nên những đối tượng thu thập thông tin trái phép thường tạo nhiều tài khoản giả và sử dụng nhiều kỹ thuật khác nhau như giả địa chỉ IP để qua mặt các biện pháp kiểm soát.
Trước khi xem xét chi tiết các biện pháp phòng chống tấn công thu thập thông tin trái phép, chúng ta cần nhìn lại thực tế sử dụng và vấn đề pháp lý. Không phải hoạt động thu thập thông tin trên web nào cũng là xấu. Ví dụ về việc thu thập thông tin hợp pháp thường được hỗ trợ bởi bot bao gồm các trang web tổng hợp như trang web du lịch, cổng đặt phòng khách sạn và trang web bán vé buổi hòa nhạc. Các bot phân phối nội dung từ các trang web này lấy dữ liệu thông qua API hoặc trích xuất dữ liệu từ trang web và thường hướng lưu lượng truy cập đến trang web của chủ sở hữu dữ liệu. Trong trường hợp này, bot có thể đóng vai trò quan trọng trong mô hình kinh doanh của họ.
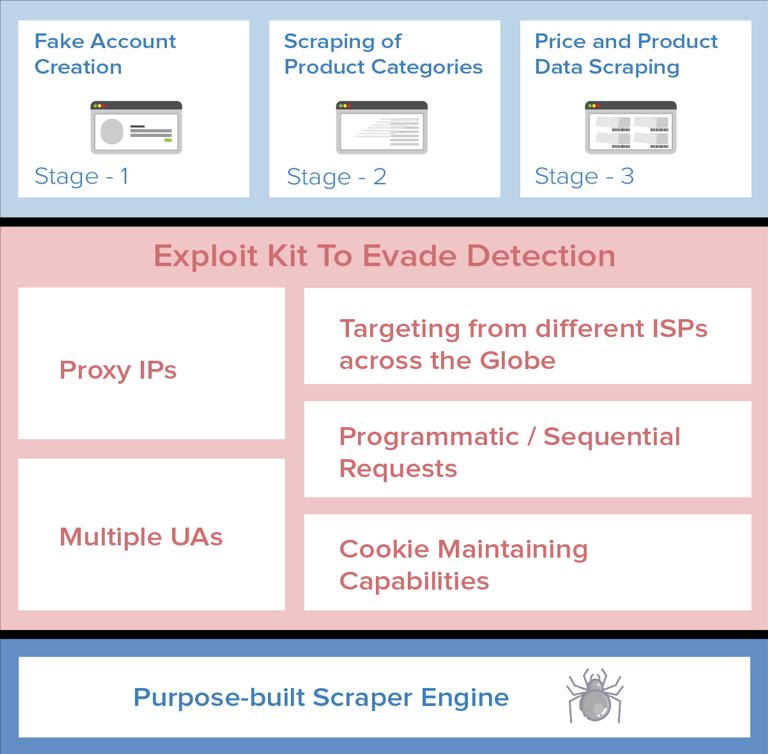
Các kỹ thuật tránh phát hiện và các bước tấn công của bot thu thập thông tin
Mặc dù thu thập thông tin trên web rất phổ biến nhưng quy định pháp lý liên quan tới hoạt động này chưa rõ ràng. Nhiều điều luật khác nhau có thể áp dụng cho việc thu thập thông tin trái phép, bao gồm luật về thương mại, bản quyền. Vì các bot thu thập thông tin cũng có thể gây hại cho doanh nghiệp chúng ta cần tạo ra một hệ sinh thái vừa thân thiện với bot, vừa có thể chặn các ứng dụng tự động độc hại. Chủ sở hữu trang web có thể cải thiện đáng kể tính bảo mật cho trang web của họ bằng cách chặn các bot xấu mà không loại trừ các bot hợp pháp.
Các cuộc tấn thông thu thập thông tin gây thiệt hại lớn nhưng không được quan tâm
Các cuộc tấn công bằng bot có thể bao gồm bất cứ điều gì từ việc tìm kiếm trên web, nơi các bot được sử dụng để thu thập nội dung hoặc dữ liệu, đến những bot cố gắng vượt qua CAPTCHA, hay gian lận quảng cáo, gian lận thẻ và gian lận kho hàng (qua mặt khách hàng tranh mua những mặt hàng giảm giá đặc biệt rồi bán lại kiếm lời hoặc đặt hàng vào giỏ nhưng không thanh toán khiến khách hàng thực sự không mua được).
Google đã ủy quyền cho Forrester – công ty nghiên cứu và tư vấn công nghệ nổi tiếng của Mỹ – nghiên cứu, xem xét các phương pháp quản lý bot. Cuộc nghiên cứu đã thu thập câu trả lời của 425 người có trách nhiệm quản lý gian lận, phát hiện và phản ứng tấn công cũng như bảo vệ dữ liệu người dùng tại các công ty Mỹ, Anh, Canada, Pháp, Đức, Australia và New Zealand. Kết quả khảo sát cho thấy, hầu hết các tổ chức chỉ đang tự bảo vệ mình trước gian lận thẻ, gian lận quảng cáo. Chỉ có 15% doanh nghiệp hiện đang tự bảo vệ mình trước các cuộc tấn công thu thập thông tin, nhưng 73% trong số đó đang phải đối mặt với cuộc tấn công như vậy hàng tuần.
Theo kết quả khảo sát được thực hiện vào tháng 11/2020 của Google, 71% công ty đã nhận thấy sự gia tăng số lượng các cuộc tấn công thu thập thông tin thành công và 56% công ty cho biết đã thấy các loại tấn công khác nhau, nhưng nhiều công ty đang sử dụng sai công nghệ để bảo vệ chính họ. Nghiên cứu cũng phát hiện rằng trong khi 78% các tổ chức đang sử dụng các biện pháp phòng chống DDoS, chẳng hạn như tường lửa ứng dụng web và mạng phân phối nội dung (Content Distribution Network - CDN), thì chưa đến 1/5 trong số họ đang sử dụng "hệ thống quản lý bot hoàn chỉnh".
Kelly Anderson, Giám đốc tiếp thị sản phẩm của nền tảng đám mây Google cho biết: “Bot tấn công logic kinh doanh của ứng dụng và chỉ có giải pháp quản lý bot mới có thể bảo vệ khỏi loại mối đe dọa này. Để bảo vệ hiệu quả các ứng dụng web khỏi các cuộc tấn công của bot, các tổ chức phải sử dụng các công cụ như bảo vệ DDoS, Web Application Fỉewall hoặc CDN, cùng với giải pháp quản lý bot".
Theo Anderson, việc thiếu mối liên hệ giữa các nhóm hoạt động bảo mật và an ninh ứng dụng với các chuyên gia thương mại điện tử, gian lận và an ninh mạng đã cho phép các bot gây ra mối đe dọa cho hoạt động kinh doanh. Quản lý bot hiệu quả dựa vào sự hợp tác giữa nhiều nhóm trong một tổ chức, bao gồm bảo mật, trải nghiệm khách hàng, thương mại điện tử và tiếp thị. Nhưng trung bình, chỉ có hai nhóm tham gia vào quản lý bot, thường là nhóm bảo mật và an ninh ứng dụng. Việc không có sự kết nối giữa các nhóm có thể dẫn đến việc các chuyên gia thương mại điện tử hoặc gian lận bị loại khỏi các quyết định quản lý bot quan trọng.
Gần 2/3 số người được hỏi cho biết họ đã mất từ 1% đến 10% doanh thu chỉ vì các cuộc tấn công thu thập thông tin. Tuy nhiên, nhiều doanh nghiệp chỉ tập trung vào các hình thức tấn công phổ biến hơn là các cuộc tấn công có thể gây ra thiệt hại lớn nhất cho lợi nhuận của họ.
Biện pháp phòng chống
Các doanh nghiệp nên thực hiện hành động pháp lý chống lại những kẻ thu thập thông tin bất hợp pháp, cảnh báo họ bằng những điều khoản dịch vụ của mình và áp dụng các biện pháp bảo mật khác như danh sách đen và danh sách trắng các địa chỉ IP, định cấu hình quyền truy cập chống lại thu thập thông tin và ngăn chặn Hotlinking (hành vi sao chép URL của chủ website để chèn vào trong website khác). Tốt nhất là sử dụng một giải pháp phát hiện, xác định và giảm thiểu bot toàn diện.
Các phương pháp phân loại và phòng chống bot, phát hiện các bot thu thập thông tin trái phép bao gồm:
- Dùng tệp robots.txt để cảnh báo các bot rằng chúng không được chào đón. Cách này chỉ phòng người ngay chứ không chống được kẻ gian vì những bot xấu không tuân thủ luật và luôn bỏ qua các cảnh báo. Trong một số tình huống, có những bot độc hại còn nhòm ngó trong tệp robots.txt để tìm thông tin mật như các thư mục riêng tư, các trang quản trị mà chủ trang web muốn giấu Google để lợi dụng những thông tin đó.
- Dùng công cụ phân tích so sánh cấu trúc các yêu cầu và thông tin header với những gì mà bot tự nhận để xác định danh tính thực của bot và chặn chúng nếu cần.
- Dùng các cấu phần web như Modenizr để chủ động đánh giá hành vi khách ghé thăm (ví dụ như có hỗ trợ cookie và JavaScript không), sử dụng CAPTCHA để phân biệt người dùng thực và bot để ngăn chặn một số kiểu tấn công. Có thể xem xét những hoạt động liên quan tới một loại bot cụ thể để định danh và phân loại chúng. Phần lớn bot liên kết với một chương trình như JavaScript, Internet Explorer hay Chrome. Nếu bot cư xử khác với những chương trình này, chúng ta có thể dùng sự khác biệt đó để phát hiện và chặn chúng.
- Sử dụng các liên kết ẩn để bẫy và phát hiện bot. Vì người dùng thông thường không thể nhìn thấy các liên kết ẩn nên khi có khách truy cập liên kết ẩn thì có thể chắc rằng đó chính là bot và chặn tất cả các yêu cầu của chúng.
- Xem xét các tài khoản người dùng mới (hay tài khoản cũ nhưng không mua hàng) thực hiện hàng loạt các truy vấn. Những tài khoản đó có thể được sử dụng bởi bot.
- Không bỏ qua những lưu lượng bất thường trên một số sản phẩm cụ thể. Người bán hàng cần giám sát để phát hiện số lượng truy cập cao bất thường vào trang của một vài sản phẩm cụ thể. Nếu không phải vào mùa cao điểm thì một sự gia tăng đột biến lượng truy cập có thể là dấu hiệu của các bot.
- Theo dõi giá của các đối thủ cạnh tranh để phát hiện dấu hiệu điều chỉnh giá nhằm mục đích cạnh tranh. Nhiều công ty dùng bot hoặc thuê các chuyên gia thu thập thông tin sản phẩm và giá của đối thủ rồi điều chỉnh giá bán nhằm thu hút khách hàng. Nếu đối thủ luôn “chạy theo” các sản phẩm và chào giá “thấp hơn” một chút thì đó chính là dấu hiệu đáng ngờ.
- Triển khai các tính năng xác định các thao tác tự động từ những hành vi tưởng như hợp lệ của người dùng. Những loại bot tinh vi có thể giả lập sự di chuyển của chuột, thực hiện các cú nhấn chuột ngẫu nhiên và di chuyển giữa các trang theo kiểu gần giống con người. Để ngăn chặn những kiểu tấn công cao cấp đó cần đến những mô hình hành vi sâu, định danh thiết bị, trình duyệt và các hệ thống điều chỉnh dựa trên kết quả phản hồi để đảm bảo bạn không chặn nhầm người dùng thực. Các giải pháp phòng chống bot chuyên dụng có thể xác định các hành vi tự động tinh vi và ngăn chặn chúng. Còn những giải pháp truyền thống như tường lửa ứng dụng chỉ có các tính năng như theo vết cookie giả, chuỗi nhận dạng người dùng / trình duyệt (user agent) và địa chỉ IP.
Nguyễn Anh Tuấn