Tối ưu hóa tấn công BLIND SQL INJECTION
Khai thác lỗ hổng Blind SQL injection trong truy vấn sử dụng mệnh đề ORDER BY
Mệnh đề ORDER BY trong truy vấn SQL
Thông thường, để truy xuất lấy dữ liệu trên máy chủ CSDL, chúng ta thường sử dụng mệnh đề “SELECT”. Cấu trúc của một truy vấn SQL sử dụng mệnh đề “SELECT” như sau:
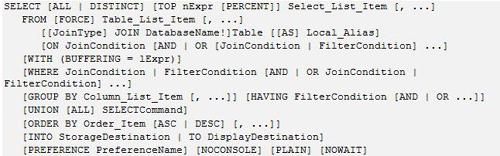
Trong đó bao gồm nhiều mệnh đề quen thuộc như mệnh đề WHERE để lọc điều kiện trong truy vấn, hay mệnh đề LIMIT để giới hạn số lượng kết quả trả về, ngoài ra, trong đó còn có mệnh đề ORDER BY. Mệnh đề này được sử dụng để sắp xếp dữ liệu trước khi trả về theo mong muốn. Ví dụ, thực hiện 2 câu lệnh: “SELECT * FROM users ORDER BY id” (1) và “SELECT * FROM users ORDER BY point” (2). Phân tích kết quả trả về của 02 câu lệnh, trong câu lệnh thứ nhất, các dòng (row) trả về được sắp xếp theo số id, theo chiều tăng dần. Với câu lệnh thứ hai, các dòng trả về được sắp xếp theo số point. Trường hợp muốn sắp xếp theo thứ tự giảm dần, chỉ cần thêm DESC vào sau mệnh đề ORDER BY. Như vậy, cùng một nội dung trả về, tùy theo cách sắp xếp dữ liệu mà mỗi truy vấn sẽ cho ra một hình thái kết quả khác nhau (về mặt thứ tự).
Lỗ hổng SQL Injection trong truy vấn sử dụng mệnh đề ORDER BY
Thông thường, dữ liệu người dùng thường được thêm vào mệnh đề WHERE, tuy nhiên trong một số trường hợp, ứng dụng sẽ cho phép người dùng tùy biến việc sắp xếp dữ liệu (theo tên, điểm số…). Nếu lập trình viên xử lý không tốt sẽ dẫn đến mắc phải lỗ hổng SQL injection. Hình 1 cho thấy một ví dụ về mã nguồn có sử dụng mệnh đề ORDER BY.

Hình 1: Mã nguồn chương trình
Biến $sort từ người dùng được thêm trực tiếp vào sau mệnh đề ORDER BY. Như vậy, kẻ tấn công hoàn toàn có thể điều khiển được phần sau của câu truy vấn. Lưu ý rằng, mệnh đề ORDER BY dùng để sắp xếp, thao tác các dữ liệu đã có (ở phần trước của mệnh đề ORDER BY), chính vì thế không thể sử dụng kỹ thuật UNION để lấy thêm dữ liệu (như tấn công SQL Injection thông thường). Vì vậy, để khai thác lỗ hổng SQL injection trong trường hợp này cần sử dụng phương pháp Blind SQL Injection.
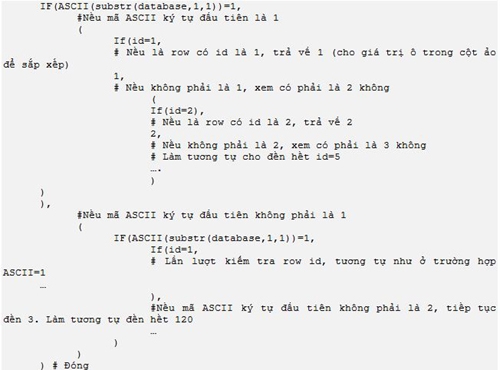
Trong tấn công khai thác lỗi Blind SQL injection, thông tin không được hiển thị trực tiếp trong dung nội trả về (thông qua thông báo lỗi, hay qua thông tin có thể thấy được từ CSDL). Do đó, kẻ tấn công không thể thấy được dữ liệu được trích xuất từ CSDL. Thay vào đó, kẻ tấn công sử dụng cấu trúc điều kiện trong truy vấn, từ đó dẫn đến các nội dung trả về khác nhau, và tiếp tục thực hiện phân tích kết quả trả về từ phản hồi đúng, sai để tìm ra sự khác biệt. Sư khác biệt đó có thể về checksum, cấu trúc HTML, từ khóa hoặc hành vi (thời gian trả về). Từ việc phân tích sự sai khác này, kẻ tấn công có thể trích xuất ra được dữ liệu mong muốn. Phía sau mệnh đề ORDER BY có 03 dạng: col_name (Tên cột), expr (biểu thức), position (số thứ tự). Nếu như col_name, hay position là một hằng số không thể can thiệp, thì expr sẽ cho ta nhiều khả năng thực hiện tính toán sau mệnh đề ORDER BY. Trong trường hợp này, kẻ tấn công sẽ kết hợp sử dụng giá trị điều kiện và sắp xếp dữ liệu để làm sai lệch hiển thị của ứng dụng. Ví dụ để kiểm tra chữ cái đầu của giá trị tên database có phải là ký tự ‘A’ hay không, kẻ tấn công sẽ sử dụng: ?sort= if((substr(database(),1,1)='A'),id,point). Khi đó câu truy vấn được thực thi sẽ là: SELECT * FROM users ORDER BY if(substr(database,1,1)=’A’,id,point). Trong đó, đoạn substr(database,1,1)=’A’ là giá trị điều kiện kiểm tra xem chữ cái đầu của giá trị tên CSDL có phải là ký tự ‘A’ hay không, nếu đúng sẽ trả về id (thực hiện sắp xếp theo cột id), nếu sai sẽ trả về point (thực hiện sắp xếp theo cột point). Trong ví dụ, tên CSDL là: sql_orderby nên ký tự trả về sẽ là ‘s’ (Hình 2).
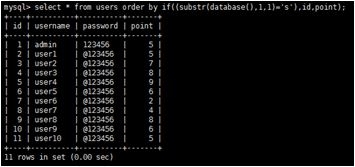
Hình 2: Trường hợp đúng (‘s’ = ‘s’). Sắp xếp theo cột id.
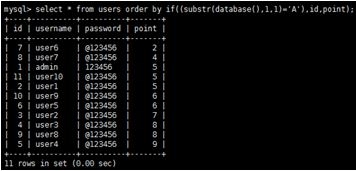
Hình 3: Trường hợp đúng (‘s’ != ‘A’). Sắp xếp theo cột point.
Trong Hình 3, nếu trường hợp đúng, dữ liệu sẽ trả về dòng có id là 1 lên trước dòng id là 2, nếu sai thì dữ liệu trả về dòng có id là 2 lên trước dòng id là 1. Bằng việc phân tích các dữ liệu trả về này, kẻ tấn công sẽ biết được chữ cái đầu của giá trị tên CSDL có phải là ký tự ‘A’ hay không.
Phương pháp tối ưu hóa tấn công Blind SQL injection bằng cách giảm số lượng yêu cầu cần gửi
Trong ví dụ trên, kẻ tấn công sẽ liên tục sử dụng phương pháp dùng các giá trị điều kiện để lấy ra được giá trị chính xác chữ cái đầu của giá trị tên CSDL. Cụ thể, kẻ tấn công lần lượt thử với toàn bộ các ký tự nhìn thấy được trong bảng mã ASCII:

Trong quá trình truy vấn, nếu kết quả trả về là đúng thì dừng lại. Trong bảng mã ASCII, có khoảng 128 ký tự nhìn thấy được, như vậy kẻ tấn công sẽ phải thực hiện gửi tối đa 128 yêu cầu cho một ký tự. Trên thế giới đã có nhiều kỹ thuật nhằm tối ưu hóa, giảm số lượng yêu cầu cần gửi.
Dưới dây là 3 phương pháp tối ưu hóa số lượng yêu cầu cần gửi của tấn công Blind SQL injection:
Tối ưu hóa bằng cách sử dụng thuật toán tìm kiếm nhị phân
Phương pháp này dựa trên thuật toán tìm kiếm nhị phân (Binary Search). Thuật toán này được áp dụng để tìm kiếm một phần tử trong một danh sách đã được sắp xếp. Có thể thấy rằng, chúng ta đang đi tìm giá trị của chữ cái trong tập danh sách các ký tự đã biết. Các ký tự này có thể sắp xếp bằng cách chuyển đổi về giá trị trong bảng mã ASCII.
Với khoảng 128 ký tự, trong đó có 96 ký tự dạng nhìn thấy được ( 26< 96 < 27), sau khi áp dụng phương pháp tìm kiếm nhị phân, chỉ cần khoảng 7 yêu cầu là có thể lấy được 1 ký tự. Tuy nhiên, phương pháp này có nhược điểm là phải thực hiện tuần tự 7 yêu cầu. Vì kết quả yêu cầu trước sẽ quyết định nội dung của yêu cầu tiếp theo.
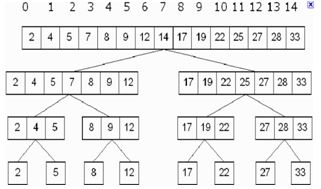
Hình 4: Thuật toán tìm kiếm nhị phân
Tối ưu hóa bằng cách sử dụng kỹ thuật dịch bit (Bit Shifing)
Mỗi ký tự đều tương ứng với một giá trị trong bảng mã ASCII. Giá trị này từ 0 đến 127 đối với hệ cơ số thập phân, nếu chuyển sang hệ nhị phân thì giá trị này sẽ được biểu diễn bằng 7 bit.

Sử dụng kỹ thuật dịch bit cho phép lấy ra giá trị từng bit của ký tự. Với mỗi ký tự lúc này chỉ là 0 hoặc 1, nên chỉ cần 1 yêu cầu để xác định bit đó (1 hay 0). Với 7 bit sẽ cần 7 yêu cầu để xác định đúng chính xác ký tự.
So với phương pháp tìm kiếm nhị phân, phương pháp dịch bit có ưu điểm cho phép thực hiện 7 yêu cầu không tuần tự, có thể thực hiện, độc lập với nhau. Tuy nhiên, nhược điểm của phương pháp này là luôn cần 7 yêu cầu để lấy được một ký tự.
Tối ưu bằng cách dùng phép dịch bit dựa vào kết quả đã được đánh chỉ mục
Phương pháp này là phương pháp dịch bit cải tiến. Trong phương pháp dịch bit cơ bản tập ký tự đầu vào là 128 ký tự (không phân biệt ký tự nhìn được và không nhìn được), bất kỳ ký tự nào cũng cần 7 lần yêu cầu để xác định. Trong khi có những ký tự khi chuyển sang dạng nhị phân có độ dài chỉ là 3, nên thực tế chỉ cần 3 yêu cầu là có thể xác định được.
Việc sử dụng phương pháp tối ưu bằng cách dùng phép dịch bit dựa vào kết quả đã được đánh chỉ mục sẽ khắc phục các nhược điểm đó. Đầu tiên phương pháp sẽ sử dụng kỹ thuật đánh chỉ mục kết quả để giới hạn lại tập các ký tự cần kiểm tra. Đối với hệ quản trị CSDL MySQL thì sử dụng hàm FIND_IN_SET. Mã tấn công có dạng:

Kết quả trả về chính là vị trí của ký tự trong danh sách. Giả sử ký tự là ‘c’ thì sẽ trả về kết quả là 3. Tiếp theo sẽ sử dụng phương pháp dịch bit giống như trên, sử dụng hàm BIN() để chuyển về dạng nhị phân. BIN(3) là 11, cần 3 yêu cầu để xác định: Bit đầu tiên là 1? Đúng; Bit thứ hai là 1? Đúng; Bit thứ ba là 1? Không; vì không có bit thứ 3 nên thực hiện tạo Sleep để báo hiệu kết thúc chuỗi nhị phân.
Trong ví dụ trên tập danh sách dài 45, BIN(45) là 101101 cũng chỉ mất 7 yêu cầu truy vấn cho ký tự ở vị trí cuối cùng của danh sách.
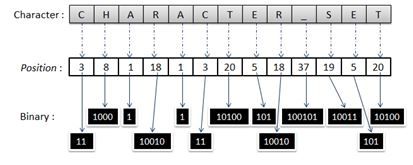
Hình 5: Ví dụ với từ CHARACTER_SET
Phương pháp tối ưu hóa dựa trên phân tích thứ tự nội dung trả về
Như vậy, để trích xuất được một ký tự cần tối thiểu 3 yêu cầu truy vấn. Kỹ thuật khai thác lỗ hổng Blind SQL injection trong trường hợp truy vấn sử dụng mệnh đề ORDER BY dựa trên kỹ thuật Blind SQL injection truyền thống, do đó cần một số yêu cầu truy vấn tương đương như vậy.
Hướng tiếp cận dựa trên phân tích thứ tự nội dung trả về
Hệ quản trị dữ liệu (Database Management System - DBMS) thực hiện lệnh ORDER BY có thể được mô tả đơn giản như sau: Sau khi DMBS thực hiện câu lệnh truy vấn (đến hết mệnh đề WHERE), kết quả truy vấn này được đặt trong vào trong một “bảng” hoặc “view”. Tiếp theo, đối với mỗi dòng của kết quả, DBMS tiếp tục thực hiện biểu thức nằm trong mệnh đề ORDER BY. Kết quả của biểu thức này sẽ được đặt trong một cột ảo, hoặc một giá trị ảo của dòng đó. Cuối cùng, DMBS thực hiện sắp xếp thứ tự các dòng (tăng dần/giảm dần) theo thứ tự đó. Có thể thấy rằng, khi chúng ta thực hiện ORDER BY id, thì một cột id’ ảo được sinh ra, giá trị của mỗi ô id’ bằng ô id của hàng đó. DBMS sẽ căn cứ cột id’ để thực hiện thuật toán sắp xếp. Tương tự, khi thực hiện lệnh ORDER BY if(substr(database,1,1)=’A’,id,point) ở trên, DBMS sinh ra 1 cột ảo, tạm gọi là sort. Giá trị ô sort này bằng ô id của dòng đó nếu chữ cái đầu tiên của biến CSDL là A, bằng ô point nếu chữ cái đó không phải là A.
Nếu giá trị trả về để sắp xếp (cột ảo được sinh ra) đang là chung cho tất cả các dòng và có cách nào đó để làm cho mỗi dòng này có giá trị ảo khác nhau, mà có thể được điều khiển bởi ký tự cần lấy, thì hoàn toàn có thể dùng cách sắp xếp để thực hiện trích xuất dữ liệu mà không cần dùng đến 128 cột như ý tưởng ở trên.
Phương pháp sắp xếp và trích xuất dựa trên thứ tự trả về của dữ liệu
Mục trên đã trình bày về ý tưởng sắp xếp nội dung trả về theo kết quả của câu truy vấn. Theo đó, với phương pháp truyền thống: câu truy vấn chính là câu điều kiện, kết quả trả về là đúng/sai, nếu kết quả điều kiện đúng, trả về nội dung sắp xếp theo cột A, nếu kết quả điều kiện sai, trả về nội dung sắp xếp theo cột B. Còn ý tưởng mới đưa ra là làm cho cột ảo được sinh ra bởi biểu thức trong mệnh đề ORDER BY có giá trị khác nhau, tương ứng với ký tự cần lấy (hoặc một bit của ký tự cần lấy). Giả sử kết quả trả về n dòng, và các dòng này có giá trị id tăng liên tục (từ 1 đến n). Số cách sắp xếp không lặp là số hoán vị của số phần tử.
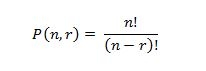
Với n là số phần tử, r là số phần tử trong hoán vị. Vì n=r nên số hoán vị là n!.
Nếu n=1, ta có 1 cách sắp xếp: 1
Nếu n=2, ta có 2 cách sắp xếp: 1 2 và 2 1 (quay lại cách khai thác truyền thống)
Nếu n=3, ta có 3!=6 cách sắp xếp: 1 2 3, 1 3 2, 2 1 3, 2 3 1, 3 1 2, 3 2 1
Nếu n=4, ta có 4!=24 cách sắp xếp
Nếu n=5, ta có 5!=120 cách sắp xếp
Nếu n=6, ta có 5!=600 cách sắp xếp
Ta chọn n=5 để chỉ lấy các ký tự nhìn thấy được. Với 120 cách sắp xếp, tương ứng với 120 ký tự có thể lấy được:
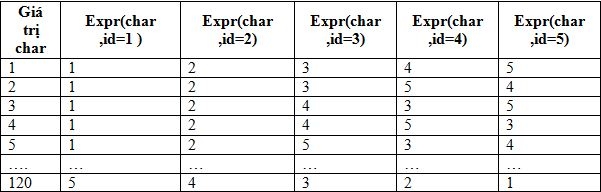
Expr(id) là biểu thức trong mệnh đề ORDER BY, nhận đầu vào là số id
Biểu thức trong mệnh đề ORDER BY có thể xây dựng như sau:
Khi đó, kẻ tấn công sẽ thực hiện phân tích thứ tự dữ liệu được trả về và so sánh với bảng tra cứu giữa vị trí và mã của ký tự để trích xuất ra được ký tự mong muốn. Phương pháp này cho phép chỉ cần một lần yêu cầu chúng ta có thể lấy về được ít nhất 1 ký tự, nếu như có từ 5 dòng trả về trở lên. Tuy nhiên, như đã thấy, nhược điểm của phương pháp này tạo ra một câu lệnh truy vấn khá dài. Ngoài ra, có thể sử dụng một phương pháp khác là áp dụng kỹ thuật dịch bit ở trên. Một ký tự khi chuyển sang ASCII rồi hệ phân có thể biểu diễn bằng 7 ký tự. Xếp 7 ký tự tương ứng với vị trí của 7 dòng trả về, lần lượt từ 1 đến 7. Nếu như mỗi dòng có thể hiển thị trạng thái của bit tương ứng thì sẽ lấy được giá trị của ký tự cần tìm. Lúc này, mỗi bit là 1 trong 2 trường hợp: 0 hoặc 1.
Để mỗi dòng có thể hiển thị được 0/1 theo bit tương ứng, ta có thể sử dụng phương pháp sau: Lấy dòng có id là 1 làm mốc và các bit từ 0 đến 6. Lần lượt thực hiện phép dịch phải bit từ 0 đến 6 để lấy từng bit một (từ phải qua trái, bit thấp đến bit cao). Vì số id đến từ 1 và mất một dòng làm mốc (id=1) nên để số bit cần dịch sẽ là (id-2). Nếu bit đó là 0, cần sắp xếp sao cho nó ở trước dòng có id là 1, nếu bit đó là 1, cần sắp xếp sao cho nó ở sau dòng có id là 1. Khi thực hiện phân tích thứ tự trả về, nếu thấy dòng n xuất hiện trước dòng 1, thì bit (n-2) từ phải sang là 0, còn xuất hiện sau dòng 1 thì bit (n-2) từ phải sang là 1, đây chính là giá trị Return (r) . Mã ASCII của ký tự là: ∑2(n-2)*r.
Để làm cho dòng đó xuất hiện trước/sau dòng 1 có thể sử dụng một cách đơn giản là: biểu thức trả về 0 nếu bit đó là 0, trả về 2 nếu bit đó là 1, đối với dòng có id là 1 thì trả về 1. Mã tấn công của phương pháp có thể được xây dựng như sau:

Thử nghiệm với bảng ví dụ ở trên:
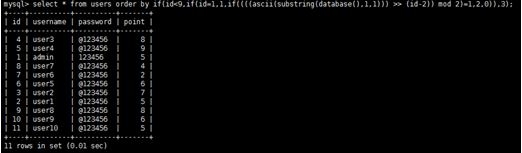
Hình 6: Áp dụng lấy ký tự đầu tiên trong tên CSDL.
Thứ tự sắp xếp là: 4 5 1 87 6 3 2. Cho vào bảng ánh xạ

Vậy ký tự cần tìm có mã nhị phân: 1110011 tương ứng với mã 115 trong bảng mã ASCII, là ký tự ‘s’. Như vậy với một lần gửi yêu cầu có thể lấy được một ký tự. Phương pháp này đòi hỏi phải có tối thiểu 8 dòng trả về, nhiều hơn so với phương pháp ở trên (5 dòng). Tuy nhiên, cách thức triển khai của phương pháp này đơn giản, dễ dàng hơn phương pháp ban đầu.
Giới hạn của phương pháp
Như đã biết, phương pháp sắp xếp và trích xuất dựa trên thứ tự trả về của dữ liệu đòi hỏi phải có tối thiểu 8 dòng trả về trong kết quả. Ngoài ra, khi áp dụng vào quá trình tấn công thực tế sẽ gặp một số vấn đề là: phải có cột id, và giá trị của cột id này phải tăng dần liên tục: Trong nhiều trường hợp cụ thể, sẽ không có cột id này, hoặc đơn giản là sẽ không biết tên cột, giá trị các id trả về không liên tục. Để khắc phục vấn đề này, cần sử dụng một biến của DBMS thay thế cho id (Hình 7), giá trị của biến này sẽ tăng dần qua mỗi dòng:

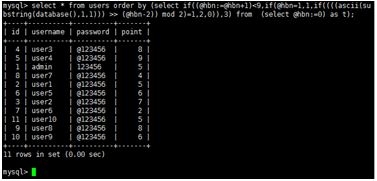
Hình 7: Sử dụng biến, thay thế sử dụng cột id
Mở rộng phương pháp
Phương pháp trên có thể mở rộng theo 02 hướng: Một là mở rộng sang các tấn công Blind SQL Injection truyền thống. Vì mệnh đề ORDER BY nằm sau mệnh đề WHERE (là mệnh đề thường xuyên mắc lỗi SQL Injection) nên hoàn toàn có thể áp dụng phương pháp này, chỉ cần kết quả trả có 8 dòng trở lên. Hai là lấy nhiều hơn 1 ký tự trong một lần yêu cầu. Để lấy 1 ký tự sẽ cần 7 dòng (cho 7 bit) và 1 dòng làm mốc. Ở ký tự thứ hai, chỉ cần thêm 7 dòng để hiển thị 7 bit tiếp theo. Với m số ký tự cần lấy, thì số dòng cần để hiển thị là 7*m+1. Hình 8 là ví dụ về việc lấy 02 ký tự trong một yêu cầu.
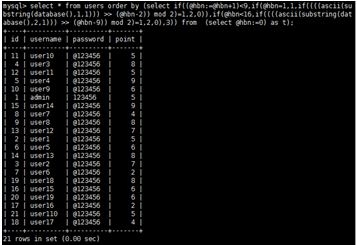
Hình 8: Lấy nhiều hơn một ký tự trong một yêu cầu
Đối với 7 cột đầu tiên (từ 2 đến 8), có 4 và 5 xuất hiện trước cột 1 nên thứ tự bit của ký tự đầu tiên là: 4 5 1 2 3 4 7. Tương tự như phần 3.2, ký tự đầu tiên là ‘s’. Đối với 7 cột tiếp theo (từ 9 đến 15), có 10 11 12 xuất hiện trước 1 nên thứ tự bit của ký tự thứ hai là: 10 11 12 1 9 13 14 15, cho vào bảng ánh xạ:

Mã ASCI của ký tự là 113, tương ứng với ký tự ‘q’. Lưu ý là số bit cần dịch sẽ là n-9 vì phải trừ thêm 7 bit cho ký tự đầu tiên. Như vậy, càng có thêm nhiều dòng trong dữ liệu trả về thì sẽ càng lấy được nhiều ký tự. Phương pháp này cho phép lấy nhiều hơn 1 ký tự trong một yêu cầu gửi đi giúp giảm số lượng yêu cầu gửi đi hơn nhiều lần so với phương pháp truyền thống.
Kết luận
Lỗi SQL injection xuất phát từ việc lập trình không an toàn, do đó giải pháp tốt nhất để khắc phục điều này là lập trình viên cần thận trọng trong việc phát triển ứng dụng web. Đối với lỗi SQL injection, có thể dùng phương pháp sử dụng Prepare Statement để khắc phục, khi đó dữ liệu đầu vào từ người dùng sẽ không được thực thi trong câu truy vấn. Đối với từng loại ngôn ngữ và CSDL cụ thể sẽ có những phương pháp áp dụng khác nhau. Còn với tấn công SQL injection trong mệnh đề ORDER BY, do vị trí của mệnh đề này không sử dụng được Prepare Statement, nên phải sử dụng phương pháp danh sách dữ liệu hợp lệ (whitelist) để khắc phục tấn công. Cần xác định việc một tập các dữ liệu hợp lệ để kiểm soát dữ liệu người dùng. Nếu dữ liệu từ người dùng nhập nằm trong whitelist hợp lệ thì sẽ được xử lý tiếp. Việc xây dựng tập dữ liệu này cũng khá đơn giản, vì thông thường nó chỉ là tên cột của bảng, là thành phần đã được xây dựng từ trước.
|
Tài liệu tham khảo 1. TS. Lương Thế Dũng, “Giáo trình An toàn Cơ sở dữ liệu”, Học Viện Kỹ Thuật Mật Mã, 2010. 2. Roberto Salgado, “SQL Injection Optimization and Obfuscation Techniques”, BlackHat EU 13, 2013. 3. Daniel Kachakil, “Fast data extraction using SQL injection and XML statements”, Kachakill, 2013. |